| dplyr | tidyr | tukeyedar |
|---|---|---|
| 1.2.0 | 1.3.2 | 0.5.0 |
37 Analyzing Two-Way Tables: The Median Polish
In previous chapters, we explored univariate and bivariate datasets–structures where each observation typically corresponds to a single value or a pair of values. In this chapter, we shift focus to a different data structure: the two-way table, where each cell contains a single value representing the intersection of two categorical factors. Unlike the datasets covered earlier, which often consist of many observations per group or variable, two-way tables typically summarize data with one value per cell, such as a mean, count, or rate. This structure requires a different analytical approach.
The median polish is an exploratory data analysis technique designed to extract the effects of row and column factors from such tables. It serves as a robust alternative to two-way ANOVA, with the goal of characterizing the contribution of each factor to the expected values in the table. Unlike traditional methods that rely on means, the median polish uses medians to iteratively adjust for row and column effects. This reliance on medians makes the technique less sensitive to outliers, providing a more robust summary of the data’s structure. Median polish is particularly useful in situations where data contains extreme values.
37.1 Introduction to Two-Way Tables
Before tackling two-way tables, let’s explore a simpler one-way table. The following dataset shows mean annual income by occupation for the year 2014 (src: Bureau of Labor Statistics)
| Income | |
|---|---|
| Architecture and Engineering | 112490 |
| Arts, Design, Entertainment, Sports, and Media | 72410 |
| Building and Grounds Cleaning and Maintenance | 83970 |
| Business and Financial Operations | 81520 |
| Community and Social Service | 70070 |
| Computer and Mathematical | 45310 |
| Construction and Extraction | 101110 |
| Education, Training, and Library | 52210 |
| Farming, Fishing, and Forestry | 55790 |
| Food Preparation and Serving Related | 76010 |
| Healthcare Practitioners and Technical | 28820 |
| Healthcare Support | 43980 |
| Installation, Maintenance, and Repair | 21980 |
| Legal | 26370 |
| Life, Physical, and Social Science | 24980 |
| Management | 38660 |
| Office and Administrative Support | 35530 |
| Personal Care and Service | 25160 |
| Production | 46600 |
| Protective Service | 45220 |
| Sales and Related | 35490 |
| Transportation and Material Moving | 34460 |
What insights can we derive from this dataset beyond the raw income values for each occupation type? To begin, we might consider summarizing the income data with a central measure, such as the median. For instance, in our working example, the median income is 45265. This single value provides a summary measure that represents the overall income distribution.
However, not all income values in the dataset are equal to 45265—they vary above or below the median. To capture this variability, we can compute deviations by subtracting the median income from each occupation’s income value. While this information can be tabulated, a dotplot provides a more visual and intuitive means of comparing these deviations.
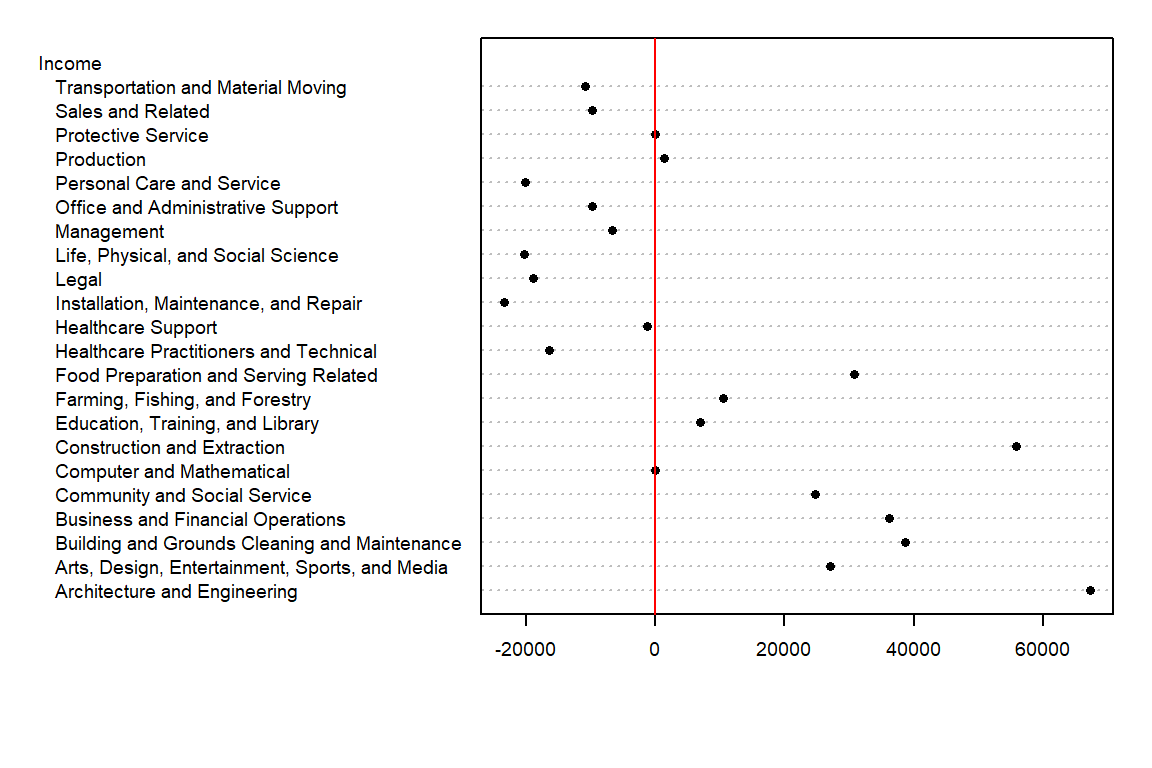
We have separated the income values into two parts: an overall and its residuals. This can be written in the following algebraic form:
\[ Income_{occupation} = Median_{income} + \varepsilon_{occupation} \]
For example, ‘Healthcare Support’ average income of 43980 can be separated into the median, 45265, and its residual, -1285.
The income value can be thought of as the response to the occupation type (also known as a factor). In other words, the factor determines the value in our table.
Next, we will see how the idea of separating the values into components can be expanded to two-way (aka two-factor) tables.
37.2 Anatomy of a two-way table
Let’s decompose the following table which represents infant mortality rates (per 1000 live births) by region and by a father’s educational attainment for the years 1964 through 1966 (Hoaglin et al.).

A two-way table is composed of three variables:
- a row factor which has four levels in our working example: Northeast, North Central, South and West,
- a column factor which has five levels in our working example: under 8, 9-11, 12, 13-15 and 16 and greater years of education,
- response variables of which we have 4 (rows) x 5 (columns) = 20 all together.
Each cell in the table contains a single summary value-such as a rate, mean, or count-rather than a collection of individual observations.
We can model the response variable, \(y_{ij}\), as the sum of a common value, a row effect, a column effect, and a residual:
\[ y_{ij} = \mu + \alpha_i + \beta_j + \epsilon_{ij} \]
where \(y_{ij}\) is the response variable for row \(i\) and column \(j\), \(\mu\) is the overall typical value (hereafter referred to as the common value), \(\alpha_i\) is the row effect, \(\beta_j\) is the column effect and \(\epsilon_{ij}\) is the residual or value left over after all effects are taken into account. This additive model forms the foundation of the median polish technique.
The goal of this analysis is to decompose the response variable into its respective effects–education and region–by iteratively removing row and column medians until the remaining residuals are minimized.
37.3 Analysis workflow
Let’s first create the dataframe.
df <- data.frame(row.names = c("NE","NC","S","W"),
ed8 = c(25.3,32.1,38.8,25.4),
ed9to11 = c(25.3,29,31,21.1),
ed12 = c(18.2,18.8,19.3,20.3),
ed13to15 = c(18.3,24.3,15.7,24),
ed16 = c(16.3,19,16.8,17.5)
)37.3.1 Visualizing patterns in two-way tables
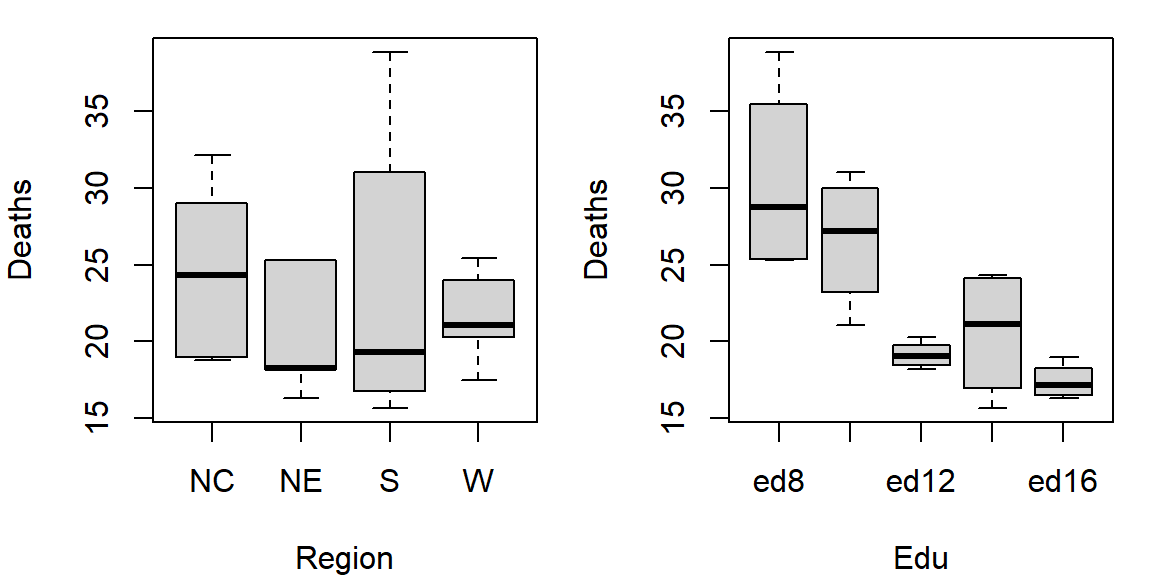
It’s often easier to look at a graphical representation of the data than a tabular one. Even a table as small as this can benefit from a plot.
We will adopt Bill Cleveland’s dotplot for this purpose. R has a built-in dotplot function called dotchart. It requires that the table be stored as a matrix instead of a dataframe; we will therefore convert df to a matrix by wrapping it with the as.matrix() function.
dotchart( as.matrix(df), cex=0.7)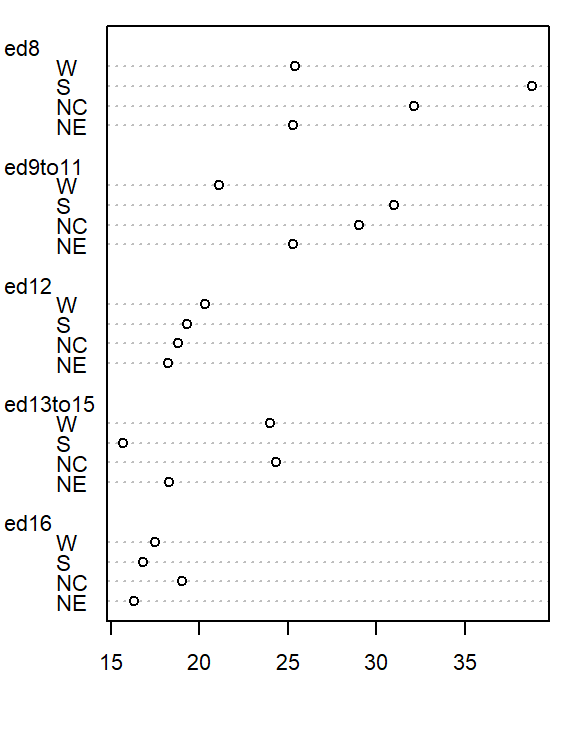
The plot helps visualize any differences in mortality rates across different father educational attainment levels. There seems to be a gradual decrease in child mortality with increasing father educational attainment.
However, the plot does not help spot differences across regions (except for the ed12 group). We can generate another plot where region becomes the main grouping factor. We transpose the matrix so that regions become the primary grouping variable on the y-axis, allowing us to compare mortality rates across regions for each education level..
dotchart( t(as.matrix(df)), cex=0.7)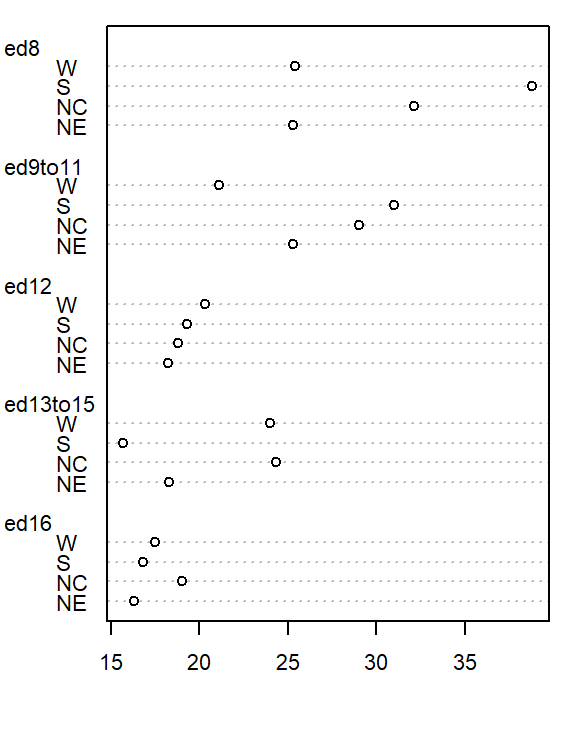
At first glance, there seems to be higher death rates for the NC and S regions and relatively lower rates for the W and NE regions. But our eyes may be fooled by outliers in the data.
Next, we’ll generate side-by-side boxplots to compare the effects between both categories. Note that we’ll need to create a long version of the table using the tidyr package.
library(tidyr)
library(dplyr)
df.l <- df %>%
mutate(Region = as.factor(row.names(.)) ) %>%
pivot_longer(names_to = "Edu", values_to = "Deaths", -Region) %>%
mutate(Edu = factor(Edu, levels=names(df)))
# side-by-side plot
OP <- par(mfrow=c(1,2))
plot(Deaths ~ Region + Edu, df.l)
par(OP)
Together, these plots suggest that both education and region may influence infant mortality, with education appearing to have a stronger effect.
Next we will attempt to quantify these effects using Tukey’s median polish.
37.3.2 Median polish
A median polish is an iterative process whereby we seek to extract the effects from the data into their row and column components. The steps involved in each iteration are described next.
37.3.2.1 Step 1: Compute overall median and residual table
First, we will compute the median value for all values in the dataset; this will be our first estimate of the common value. The resulting median value is placed in the upper left-hand margin of the table. A residual table is created by taking the difference between the original value and the overall median.
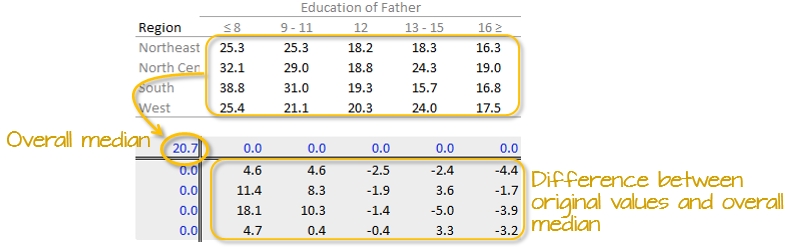
You’ll also note that the row and column effect values are initially populated with 0 values.
37.3.2.2 Step 2: Compute the row medians
Next, row medians are computed (shown in red in the following figure) from the residual table.
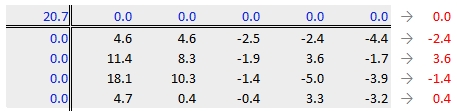
Note that in addition to computing the row median values for the response variable, we are also computing the median value for the column effects in the upper margin (which happens to be zero since we have no column effect values yet).
37.3.2.3 Step 3: Create a new residual table from the row medians
The row medians are added to the left hand margin of the new residual table (shown in green). These values represent the row effects in this first iteration. A new set of residual values is created from the row medians where each cell takes on the value of the subtraction of the row median from each response variable in that row.
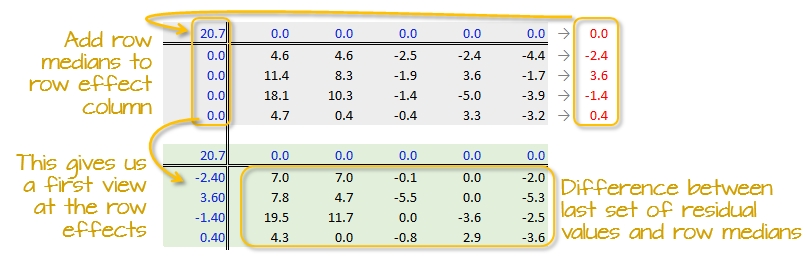
The subtraction is also done for the column effect values (even though all values remain zero) and the global median (common effect value).
37.3.2.4 Step 4: Compute the column medians
Next, column medians are computed (shown in red in the following figure) from the residual table. Note that you are NOT computing the column medians from the original response variables. Note too that we are also computing the median value for the row effect values (left margin).
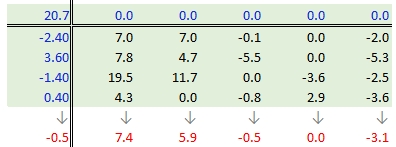
37.3.2.5 Step 5: Create a new residual table from the column medians
A new residual table is created from the column medians where each new cell takes on the value of the subtraction of the column median from each initial residual value in that column. For example, the first upper-left cell’s residual is \(7.0 - 7.4 = -0.4\).
The column medians are also added to the column effect margin. Note that we are also adding the row effect median value, -0.5, to the common effect cell in the upper left-hand corner.
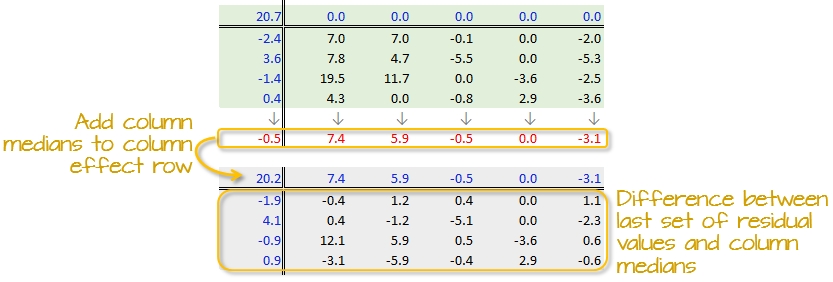
We have now completed our first row and column smoothing iteration. However, there may be more row and column effects that can be pulled from the residuals. We therefore move on to a second iteration.
37.3.2.6 Step 6: Second iteration – row effects
Next, we compute the row medians from the residuals, then add the column effect median to the top margin (and the common value) and subtract the row medians from the residuals. as in step 3.
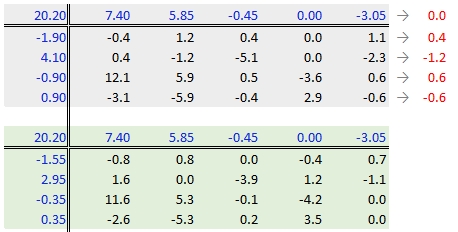
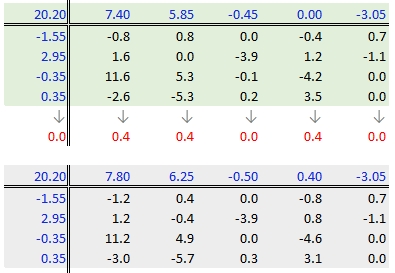
37.3.2.7 Step 7: Second iteration – column effects
To wrap-up the second iteration, we compute the column median values from the residuals then subtract the medians from those residuals. We also add the medians to the row effect values and the common value.
37.3.2.8 When do we stop iterating?
The goal is to iterate through the row and column smoothing operations until the row and column effect medians are close to 0. However, Hoaglin et al. (1983) warn against “using unrestrained iteration” and suggest that a few steps should be more than adequate in most instances.
In our working example, a third iteration may be warranted. The complete workflow for this third iteration follows.
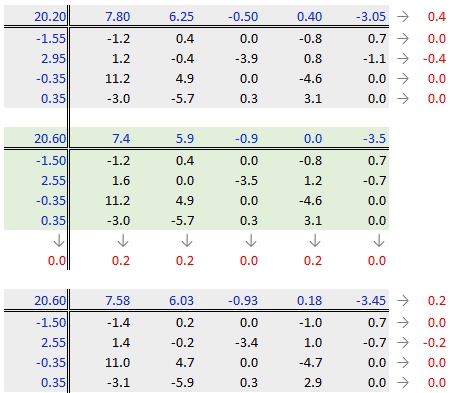
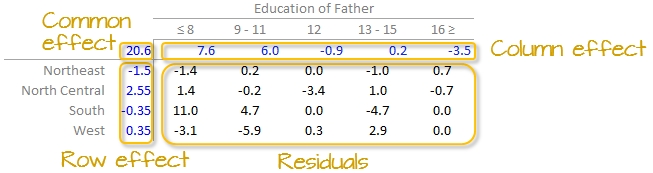
The final version of the table (along with the column and row values) is shown below:
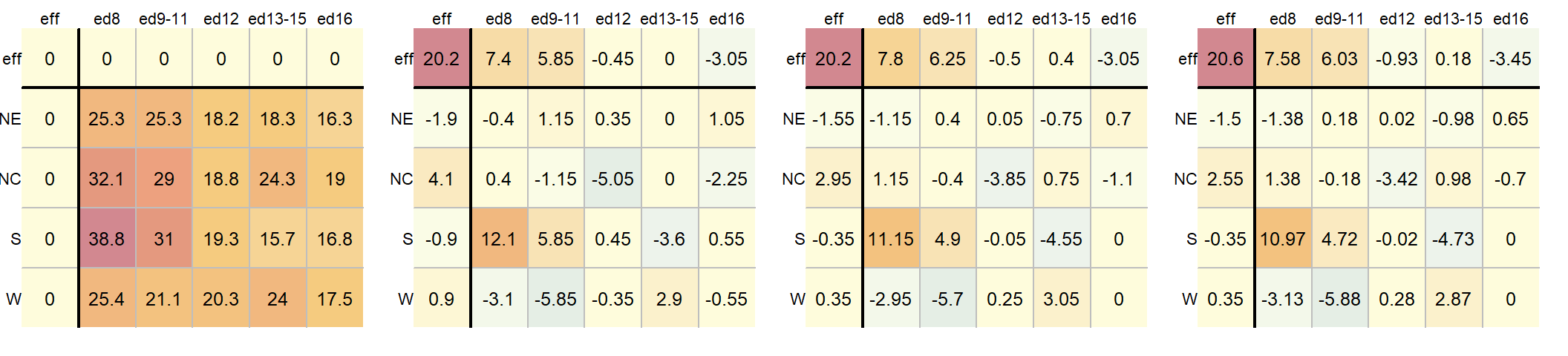
A progression of each iteration is shown side-by-side in the next figure. The left-most table is the original data showing death rates. The second table shows the outcome of the first round of polishing (including the initial overall median value of 20.2). The third and forth table show the second and third iterations of the smoothing operations.
A few takeway observations from the analysis follow:
- The common effect of 20.6 contributes the largest portion of the overall variation in the table.
- Between
RegionandEducationeffects,Educationexplains a greater share of the variability in infant mortality rates. Specifically, the range of theEducationeffect is 7.58 - (-3.45) = 11.03 deaths per 1000 births compared to 2.55 - (-1.5) = 4.05 deaths per 1000 births for theRegioneffect. - One notably high residual–10.97 deaths above the overall median deaths–is observed in the Southern region and for fathers with only an 8th grade education, indicating a potential outlier or area for further investigation.
37.3.3 Interpreting the median polish
As noted earlier, a two-way table represents the relationship between the response variable, \(y\), and the two categories as:
\[ y_{ij} = \mu + \alpha_i + \beta_j + \epsilon_{ij} \]
In our working example, \(\mu\) = 20.6; \(\alpha_i\) = -1.5, 2.6, -0.4, and 0.4 for \(i\) = NE, NC, S and W respectively; \(\beta_j\) = 7.6, 6.0, -0.9, 0.2 and -3.5 for \(j\) = ed8, ed9to11, ed12, ed13to15 and ed16 respectively.
The residuals represent the portion of the mortality rates that can’t be explained by either factors.
So the mortality rate in the upper left-hand cell from the original table can be deconstructed as:

An examination of the table suggests that the infant mortality rate is greatest for fathers who did not attain more than 8 years of school (i.e. who has not completed high school) as noted by the high column effect value of 7.6. This is the rate of infant mortality relative to the overall median (i.e. on average, 20.6 infants per thousand die every year and the rate goes up to 7.6 + 20.6 = 28.2 for infants whose father has not passed the 8th grade). Infants whose father has completed more than 16 years of school (i.e. who has completed college) have a lower rate of mortality as indicated by the low effect value of -3.5 (i.e. 3.5 fewer depths than average). The effects from regions also show higher infant mortality rates for North Central and Western regions (with effect values of 2.6 and 0.4 respectively) and lower rates for the northeastern and southern regions; however the regional effect does not appear to be as dominant as that of the father’s educational attainment.
It’s also important to look at the distribution of the residuals across the two-way table. One should identify unusually high or low residuals in the table. Such residuals may warrant further investigation (e.g. the high southern region residual value of 10.97 may need further exploration).
37.3.4 Test for non-additivity (interactive terms)
Thus far, we have assumed an additive relationship between the effects (factors). But this additive model may not be the best fit for our data. A good way to test this is by generating a Tukey Additivity Plot where we plot residuals vs. the comparison value, \(cv_{ij}\), defined as \(\alpha_i \beta_j / \mu\). If the plot is devoid of any obvious trend or pattern we can conclude that our dataset is consistent with an additive model. Such seems to be the case with our working example as shown in the following plot.
If the diagnostic plot revealed a trend, its shape–or more specifically, its slope–could be used in helping define an appropriate transformation for the data. A rule of thumb is to apply a \((1 – slope)\) power transformation to the original data.
If a power transformation is not appropriate for the dataset, then a non-additive (i.e. interactive) term can be added to the model. This term is often of the form \(k \cdot \alpha_i \beta_j / \mu)\) where \(\alpha_i \beta_j / \mu\) is the comparison values. The constant \(k\) is the slope estimated from the linear pattern in the diagnostic plot (i.e. the Tukey Additivity plot). The extended model thus takes the form:
\[ y_{ij} = \mu + \alpha_i + \beta_j + k(\alpha_i \beta_j / \mu) + \epsilon_{ij} \] The term \(\alpha_i \beta_j\) introduces a multiplicative interaction between the row effect \(\alpha_i\) and the column effect \(\beta_j\). While \(\alpha_i\) and \(\beta_j\) are constant effects for their respective row and column, the presence of the interactive term means their contributions to the cell value \(y_{ij}\) are not purely independent. With some algebraic manipulation, the contribution of the row effect \(\alpha_i\) can be seen as modified by the column effect \(\beta_j\):
\[ y_{ij} = \mu + \alpha_i(i + k\beta_j/\mu) + \beta_j + \epsilon_{ij} \]
or vice versa:
\[ y_{ij} = \mu + \alpha_i + \beta_j(1 + k\alpha_j/\mu) + \epsilon_{ij} \] These rearrangements demonstrate how the effect associated with one factor depends on the level of the other factor, which is the hallmark of interaction.
37.4 Implementing the median polish in R
37.4.1 Using base R’s medpolish
The steps outlined in the previous section can be easily implemented using pen and paper or a spreadsheet environment for larger datasets. R has a built-in function called medpolish() which does this for us. We can define the maximum number of iterations by setting the maxiter= parameter but note that medpolish will, by default, automatically estimate the best number of iterations for us.
df.med <- medpolish( df)1: 47.1
2: 42.9
3: 42.45
Final: 42.25The median polish ran through 4 iterations–one more than was run in our step-by-step example.
The four values printed to the console gives us the sum of absolute residuals at each iteration. The output from the model is stored in the df.med object. To see its contents , simply type it at the command line.
df.med
Median Polish Results (Dataset: "df")
Overall: 20.775
Row Effects:
NE NC S W
-1.475 2.375 -0.350 0.350
Column Effects:
ed8 ed9to11 ed12 ed13to15 ed16
7.4750 5.9250 -1.1125 0.0750 -3.6250
Residuals:
ed8 ed9to11 ed12 ed13to15 ed16
NE -1.475 0.075 0.0125 -1.075 0.625
NC 1.475 -0.075 -3.2375 1.075 -0.525
S 10.900 4.650 -0.0125 -4.800 0.000
W -3.200 -5.950 0.2875 2.800 0.000All three effects are displayed as well as the residuals (note that the precision returned is greater than that used in our earlier analysis).
To generate the Tukey additivity plot, simply wrap the median polish object with the plot command as in:
plot( df.med )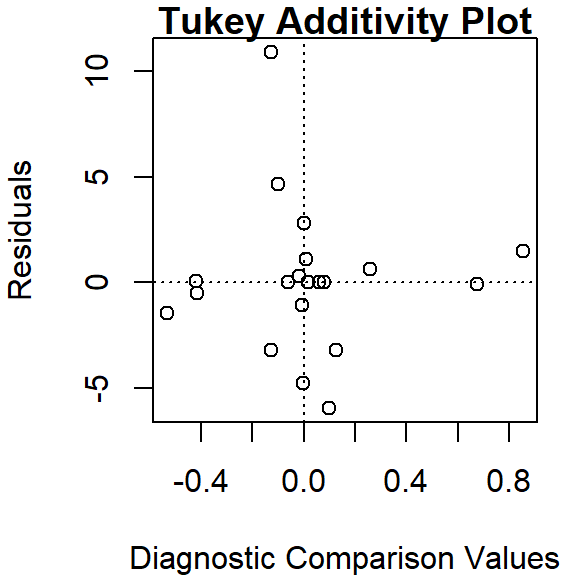
37.4.2 Using eda_pol
The tukeyedar package has a custom function called eda_pol that will output the polished table as a graphic element.
Unlike the base medpolish function, eda_pol requires that the data be in long form. In creating the long form version of the data, we’ll explicitly set the levels for educational attainment and region.
grd <- c("ed8", "ed9-11", "ed12", "ed13-15", "ed16")
reg <- c("NE", "NC", "S", "W")
dfl <- data.frame(Region = factor(rep( c("NE", "NC", "S", "W"), each = 5),
levels = reg),
Education = factor(rep( grd , 4), levels = grd),
Deaths = c(25.3, 25.3, 18.2, 18.3, 16.3, 32.1, 29, 18.8,
24.3, 19, 38.8, 31, 19.3, 15.7, 16.8, 25.4,
21.1, 20.3, 24, 17.5))The eda_pol requires that you specify which variables will be mapped to the row and column effects.
library(tukeyedar)
df.pol <- eda_pol(dfl, row = Region, col = Education , val = Deaths )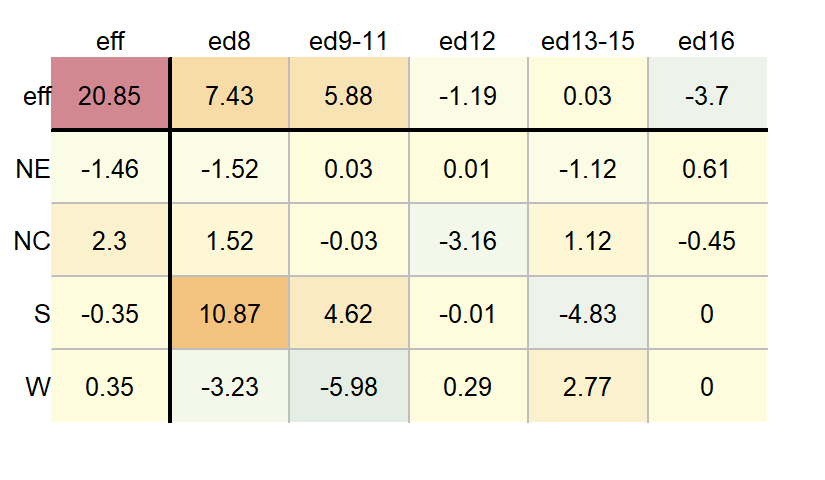
Here, the eda_pol function required five iterations which explains the slight difference in output from that generated with the medpolish function. You can control the maximum number of iterations in eda_pol with the maxiter argument.
By default, the column and row values are listed in the same order as they are presented in the input data frame (either defined alphabetically or defined by their levels). You can have the function sort the values by their effect size using the sort argument.
df.pol <- eda_pol(dfl, row = Region, col = Education, val = Deaths, sort = TRUE )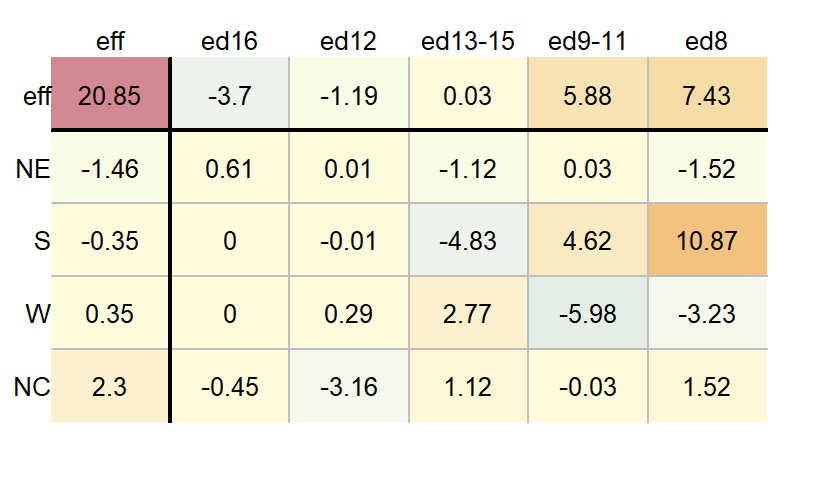
The df.pol object is a list that stores output values such as the common, row and column effects.
df.pol$global[1] 20.85df.pol$row Region effect
1 NE -1.4625
2 NC 2.3000
3 S -0.3500
4 W 0.3500df.pol$col Education effect
1 ed8 7.43125
2 ed9-11 5.88125
3 ed12 -1.19375
4 ed13-15 0.03125
5 ed16 -3.70000The eda_pol will also output a diagnostic plot.
plot(df.pol, plot = "diagnostic")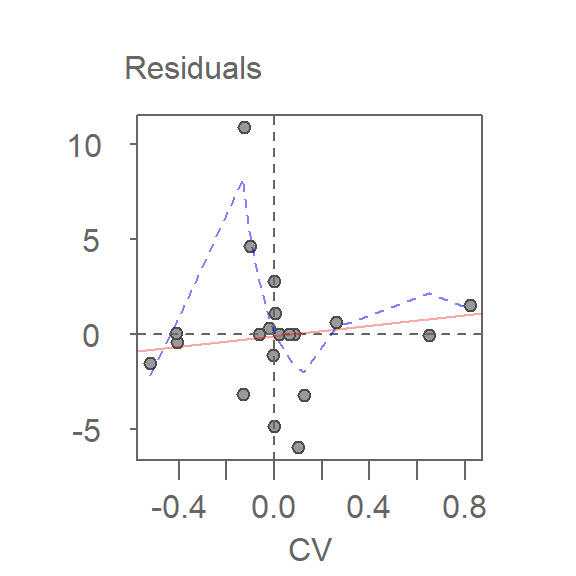
In addition to generating the plot, the function returns the slope of the fitted line in the console.
For a comprehensive review of the median polish and the eda_pol function, see the eda_pol vignette.
37.5 What if we use the mean instead of the median?
The procedure is similar with some notable differences. First, we compute the global mean instead of the medians (the common effect) then subtract it from all values in the table. Next, we compute the row means (the row effect) then subtract each mean from all values in its associated row. We finally compute the column means (from the residuals) to give us the column effect. That’s it, unlike the median polish, we do not iterate the smoothing sequences. An example of a “mean” polish applied to our data follows:
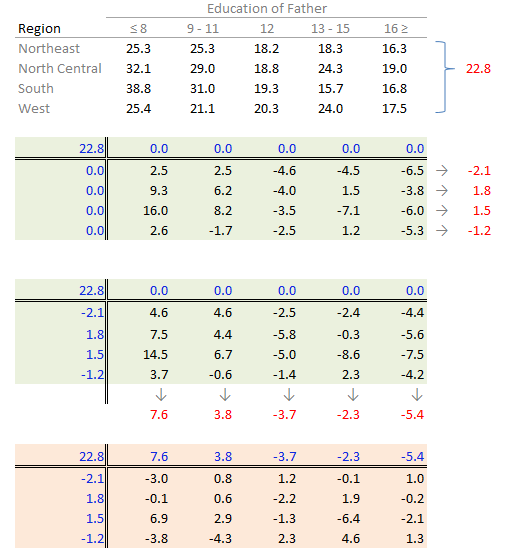
The results differ slightly from those produced using the median polish. Recall that the mean is sensitive to outliers and medians are not.
So what can we gain from the “mean” polish? Well, as it turns out, it serves as the basis of the two-way ANOVA.
37.5.1 Two-way ANOVA
A two-way ANOVA assesses whether the factors (categories) have a significant effect on the outcome. Its implementation can be conceptualized as a regression analysis where each row and column level is treated as a dummy variable. The computed regression coefficients are the same as the levels computed using the “mean” polish outlined in the previous step except for one notable difference: the ANOVA adds one of the column level values and one of the row level values to the grand mean. It then subtracts those values from their respective row/column effects.
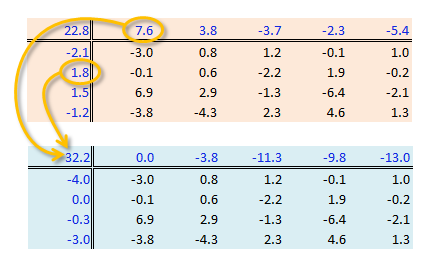
The resulting row/column levels are the regression coefficients:
M <- lm(Deaths ~ Education + Region, dfl)
coef(M) (Intercept) Educationed9-11 Educationed12 Educationed13-15 Educationed16 RegionNC RegionS
28.255 -3.800 -11.250 -9.825 -13.000 3.960 3.640
RegionW
0.980 The regression formula takes on the form:
\[ \begin{aligned} \text{Deaths} &= 32.21 - 3.8\,\text{ed9to11} - 11.25\,\text{ed12} - 9.83\,\text{ed13to15} - 13\,\text{ed16} \\ &\quad - 3.96\,\text{RegionNE} - 0.320\,\text{RegionS} - 2.980\,\text{RegionW} + \epsilon_{ij} \end{aligned} \]
For example, to compute the first value in the raw table (death rate = 25.3) using the formula, substitute the variables as follows:
\[ \begin{aligned} \text{Deaths} &= 32.21 - 3.8(0) - 11.25(0) - 9.83(0) - 13(0) \\ &\quad - 3.96(1) - 0.320(0) - 2.980(0) - 3.0 \\ &= 32.21 - 3.96 - 3.0 \\ &= 25.25 \approx 25.3 \end{aligned} \]
To assess if any of the factors have a significant effect on the Death variables, simply wrap the regression with an anova() function.
anova(M)Analysis of Variance Table
Response: Deaths
Df Sum Sq Mean Sq F value Pr(>F)
Education 4 478.52 119.630 7.7539 0.00251 **
Region 3 57.44 19.146 1.2410 0.33801
Residuals 12 185.14 15.428
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The results suggest that the father’s educational attainment has a significant effect on infant mortality (p = 0.0025) whereas the region does not (p = 0.338).
37.5.2 Visualizing a two-way ANOVA as a table
You can view the output of a two-way ANOVA as a “mean polish” table using the eda_pol function. Simply set the stat argument to mean.
df.ano <- eda_pol(dfl, row = Region, col = Education, val = Deaths, stat = mean)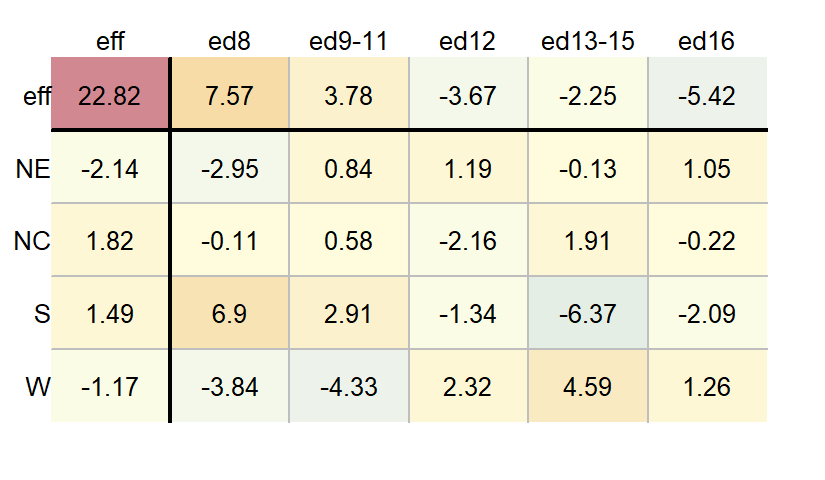
37.6 Summary
The median polish is a powerful exploratory tool for analyzing two-way tables, data structures where each cell represents a single value at the intersection of two categorical factors. Unlike traditional methods such as two-way ANOVA, which rely on means and are sensitive to outliers, the median polish uses medians to iteratively extract row and column effects offering a robust decomposition of the data.
In this chapter, we:
- Introduced the structure of two-way tables and how they differ from univariate and bivariate datasets.
- Demonstrated how to separate a one-way table into a central value and residuals.
- Extended this idea to two-way tables using the median polish algorithm.
- Visualized the iterative process of smoothing row and column effects.
- Interpreted the resulting decomposition in terms of common, row, column, and residual effects.
- Compared the median polish to its mean-based counterpart and linked it to two-way ANOVA.
- Explored diagnostic tools for assessing additivity and identifying potential interactions.
37.7 References
Understanding Robust and Exploratory Data Analysis, D.C. Hoaglin, F. Mosteller and J.W. Tukey, 1983.