| ggplot2 | tukeyedar |
|---|---|
| 4.0.2 | 0.5.0 |
29 Exploring Spread in the Residuals
So far, we’ve focused on modeling the typical value of \(y\) as a function of \(x\). The fitted model represents a measure of location (e.g., the mean) of \(y\) for infinitesimally thin slices of \(x\). In the previous chapter, we used residual-dependence (R-D) plots and residual-fit (R-F) plots to refine the model’s fit and evaluate its accuracy.
In the univariate analysis portion of this course, we emphasized the importance of maintaining a consistent spread of residuals across groups. A uniform residual spread simplified comparisons between groups by reducing the analysis to a comparison of their means.
Similarly, ensuring a consistent spread of residuals (i.e. variability of residuals) across the full range of the independent variable in bivariate analysis is crucial. This consistency not only offers explanatory clarity but is also critical for many statistical procedures that assume homoscedasticity (constant variance) in the residuals. Violations of this assumption can compromise the validity of these methods. Uneven spread can affect confidence intervals, hypothesis tests, and predictions-especially in parametric models.
29.1 The spread-location plot
While inconsistency in spread across the full range of dependent variables can be sometimes observed in a residual-dependence plot, certain patterns in the data can make such an assessment more challenging in such a plot.
A spread-location plot (S-L plot) is designed to explore changes in spreads as a function of increasing fitted values. The plot pits an expression of spread, typically the square root of the residuals’ absolute value, as a function of the fitted values. To help gauge the shape of this distribution, a non-parametric curve, such as the loess, is fitted to the data.
An example of a homoscedastic set of residuals follows. The plot on the left is the regression model and the plot on the right is the resulting residuals S-L plot.
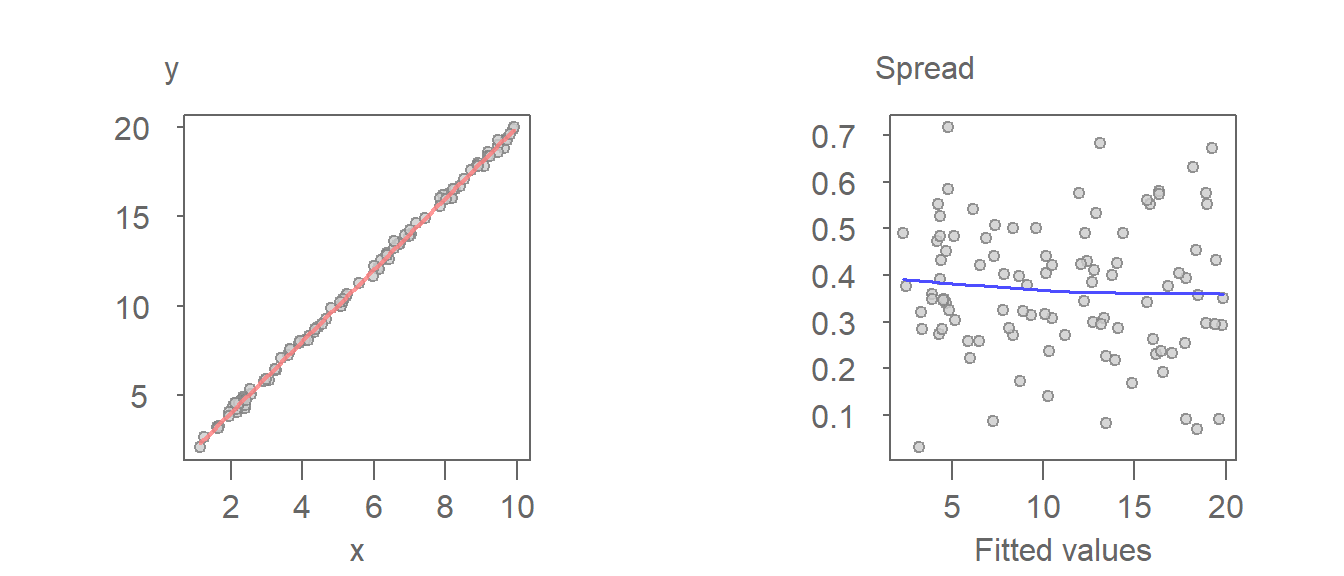
In an S-L plot, a flat loess line indicates constant spread. A rising or falling trend suggests increasing or decreasing variability, which may violate model assumptions.
Here, the residuals are constant across the full range of fitted values. This is confirmed by the loess fit which shows no significant deviation from a horizontal line.
This next example is that of a model that generates a heteroscedastic set of residuals.
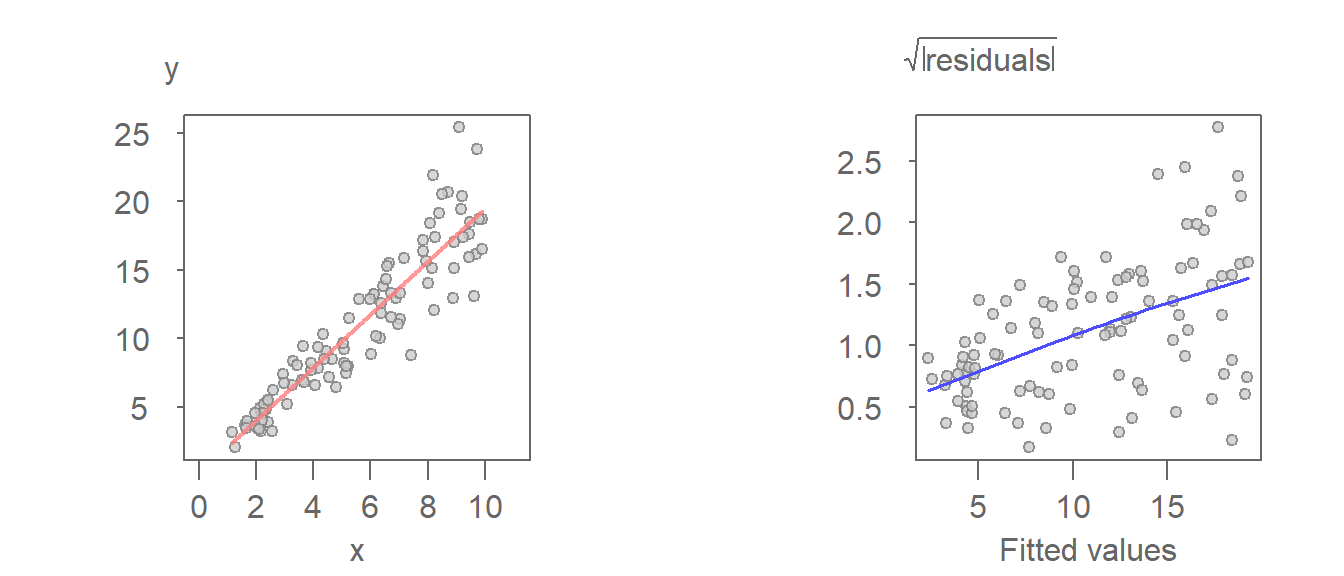
The increasing spread as a function of increasing fitted value is apparent in the S-L plot (right-plot). It can also be observed in the \(Y\) vs. \(X\) plot (left plot). Note that the residual is the distance between the fitted line and each point when measured parallel to the \(Y\) axis.
29.2 The spread-dependence plot
For bivariate models, an alternative to the S-L plot is the spread-dependence (S-D) plot where the independent variable, \(X\), is plotted on the x-axis instead of the fitted values. This alternate form of the S-L plot is better suited for models that take on a quadratic form. S-L plots use fitted values on the x-axis, which can obscure patterns when the model is nonlinear. S-D plots use the original independent variable, making it easier to detect spread patterns tied directly to \(X\).
For example, the following fitted model shows a monotonic increase in spread with increasing x-value. However, the S-L plot does a poor job in picking the heteroscedasticity in the residuals.
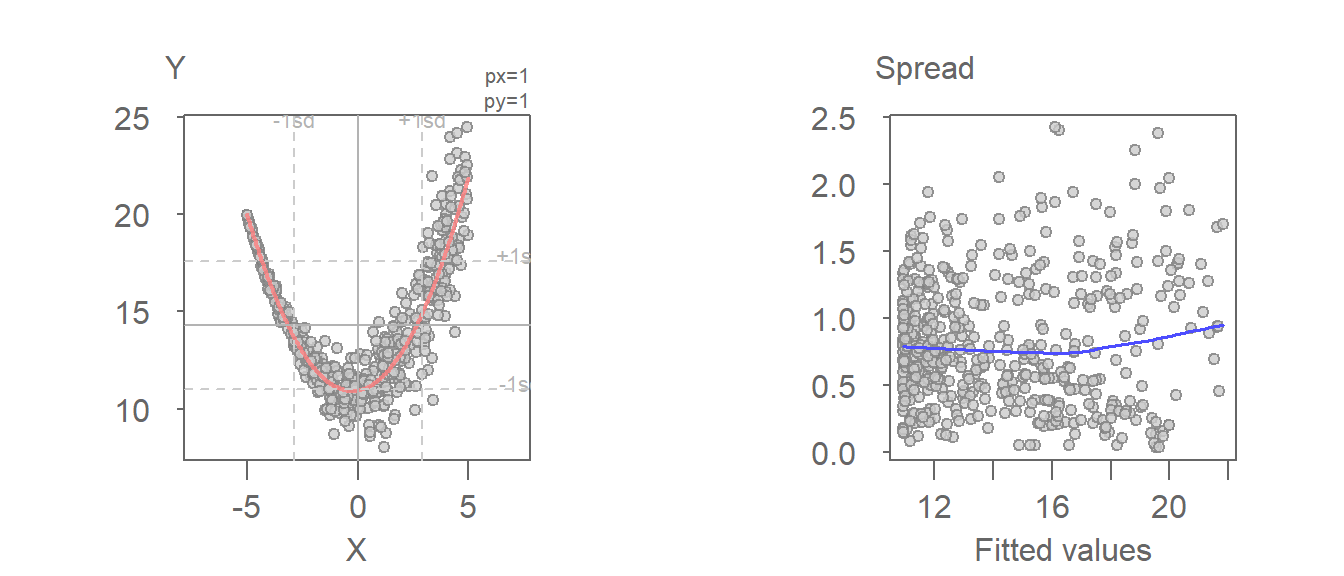
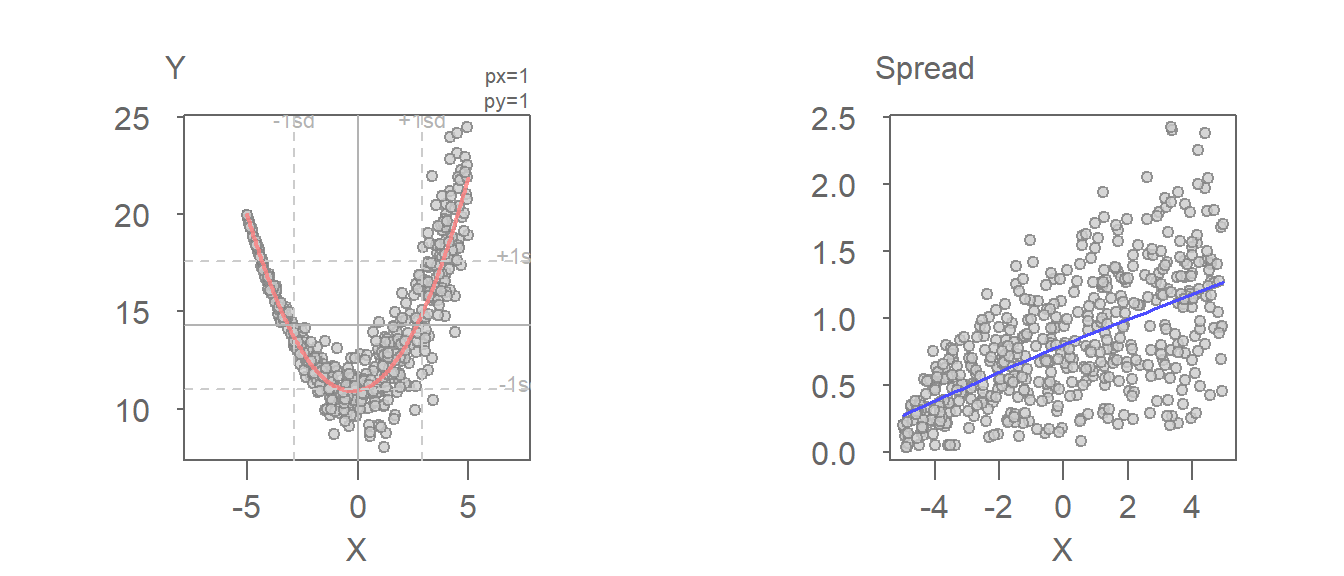
The heteroscedasticity in the residuals is far more pronounced when plotting the spread as a function of the independent variable.
29.3 Generating an S-L plot with eda_sl
If a regression model was generated using the base lm function or tukeyedar’s eda_lm function, the resulting model can be passed to the eda_sl function as follows:
library(tukeyedar)
M <- lm(mpg ~ hp, mtcars)
eda_sl(M)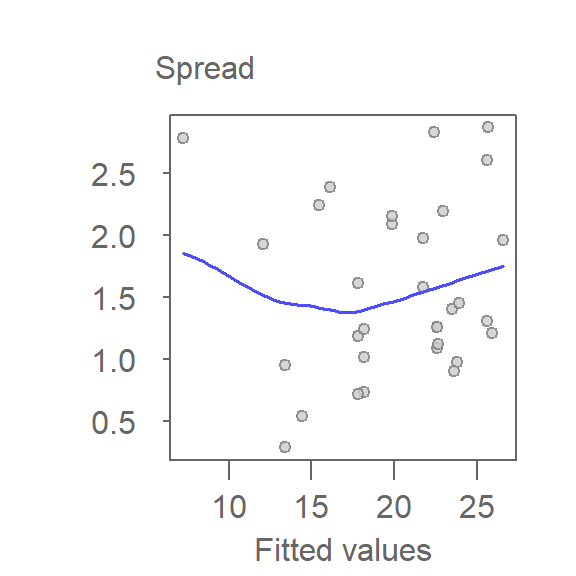
To generate an S-D plot, set the argument type to "dependence".
eda_sl(M, type = "dependence")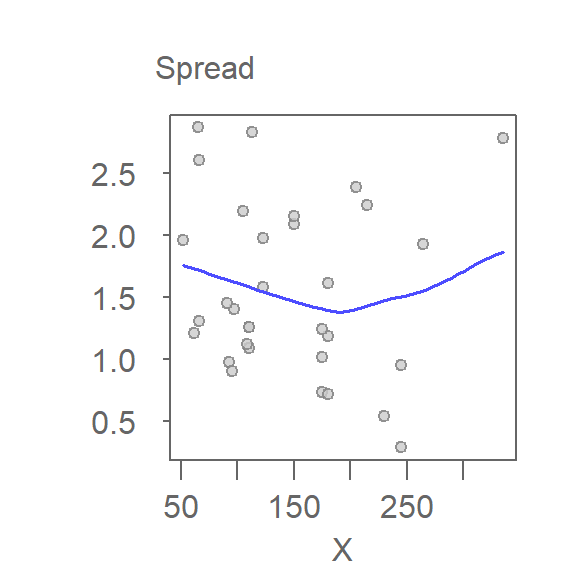
29.4 Generating an S-L plot with base plot or ggplot
Before generating an S-L plot using the base plotting environment or ggplot, the spread will need to be computed from the model output.
library(ggplot2)
sl2 <- data.frame( std.res = sqrt(abs(residuals(M))),
fit = predict(M))
ggplot(sl2, aes(x = fit, y =std.res)) + geom_point() +
stat_smooth(method = "loess", se = FALSE, span = 1,
method.args = list(degree = 1) ) +
ylab(expression(sqrt(abs(residuals)))) +
xlab("Fitted values")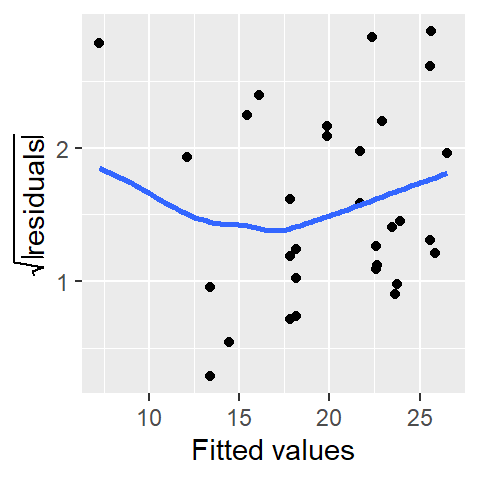
The function predict() extracts the fitted y-values from the model M and is plotted along the x-axis.
29.5 Summary
In this chapter, we explored how to assess the spread of residuals-a key component of model diagnostics. Using spread-location (S-L) and spread-dependence (S-D) plots, we visualized how residual variability changes across the range of the independent variable.
A consistent spread, or homoscedasticity, supports the validity of many statistical procedures. In contrast, heteroscedasticity-where spread increases or decreases with \(X\)-can indicate model inadequacy or the need for transformation.
By examining spread graphically, we gain deeper insight into model behavior and improve our ability to refine fits, validate assumptions, and ensure robust analysis.