| dplyr | ggplot2 | forcats | scales | hexbin |
|---|---|---|---|---|
| 1.2.0 | 4.0.2 | 1.0.1 | 1.4.0 | 1.28.5 |
15 ggplot2 plotting environment
15.1 Sample data
The data files used in this tutorial can be downloaded from the course’s website as follows:
load(url("https://github.com/mgimond/ES218/raw/refs/heads/gh-pages/Data/dat1_2.RData"))This should load several dataframe objects into your R session (note that not all are used in this exercise). The dat1l dataframe is a long table version of the crop yield dataset.
head(dat1l, 3) Year Crop Yield
1 1961 Barley 16488.52
2 1962 Barley 18839.00
3 1963 Barley 18808.27dat1l2 adds Country to the dat1l dataframe.
head(dat1l2, 3) Year Crop Country Yield
1 2012 Barley Canada 38894.66
2 2012 Maize Canada 83611.49
3 2012 Oats Canada 24954.79The dat1w dataframe is a wide table version of dat1l.
head(dat1w, 3) Year Barley Buckwheat Maize Oats Rye
1 1961 16488.52 10886.67 39183.63 15171.26 11121.79
2 1962 18839.00 11737.50 40620.80 16224.60 12892.77
3 1963 18808.27 11995.00 42595.55 16253.04 11524.11The dat2 dataframe is a wide table representation of income by county and by various income and educational attainment levels. The first few lines and columns are shown next:
dat2[1:3, 1:7] County State B20004001 B20004002 B20004003 B20004004 B20004005
1 Autauga al 35881 17407 30169 35327 54917
2 Baldwin al 31439 16970 25414 31312 44940
3 Barbour al 25201 15643 20946 24201 42629dat2c is a long version of dat2
head(dat2c, 3) State County Level Region All F M
1 ak Aleutians East Borough All West 21953 20164 22940
2 ak Aleutians East Borough NoHS West 21953 19250 22885
3 ak Aleutians East Borough HS West 20770 19671 2119215.2 The ggplot2 package
The ggplot2 package is designed around the idea that graphics can be decomposed into a formal system of grammatical rules. The ggplot2 learning curve is the steepest of all graphing environments encountered thus far, but once mastered it affords the greatest control over graphical design. For an up-to-date list of ggplot2 functions, you may want to refer to ggplot2’s website.
A plot in ggplot2 consists of different layering components, with the three primary components being:
- The dataset that houses the data to be plotted;
- The aesthetics which describe how data are to be mapped to the geometric elements (coordinates, color, shape, size, etc..);
- The geometric elements to use in the plot (i.e. points, lines, rectangles, etc…).
Additional (optional) layering components include:
- Statistical elements such as smoothing, binning or transforming the variable
- Facets for conditional or trellis plots
- Coordinate systems for defining the plots shape (i.e. cartesian, polar, spatial map projections, etc…)
To access ggplot2 functions, you will need to load its package:
library(ggplot2)From a grammatical perspective, a scientific graph is the conversion of data to aesthetic attributes and geometric objects. This is an important concept to grasp since it underlies the construction of all graphics in ggplot2.
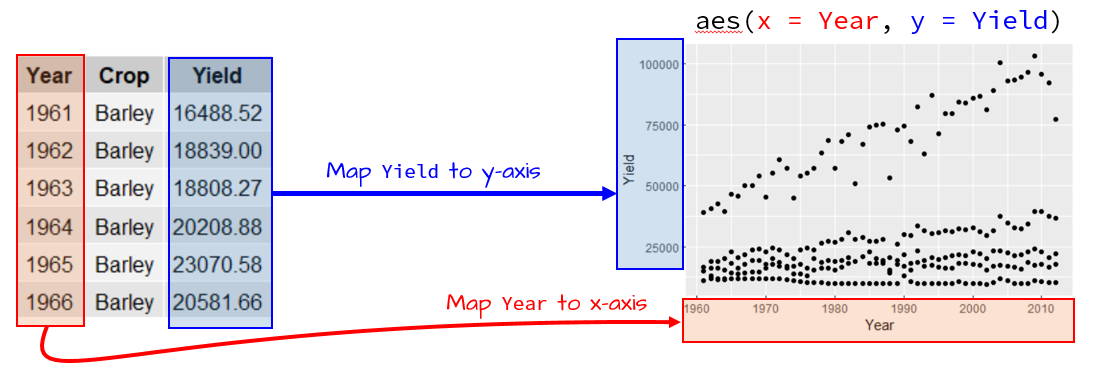
For example, if we want to generate a point plot of crop yield as a function of year using the dat1l data frame, we type:
ggplot(dat1l , aes(x = Year, y = Yield)) + geom_point()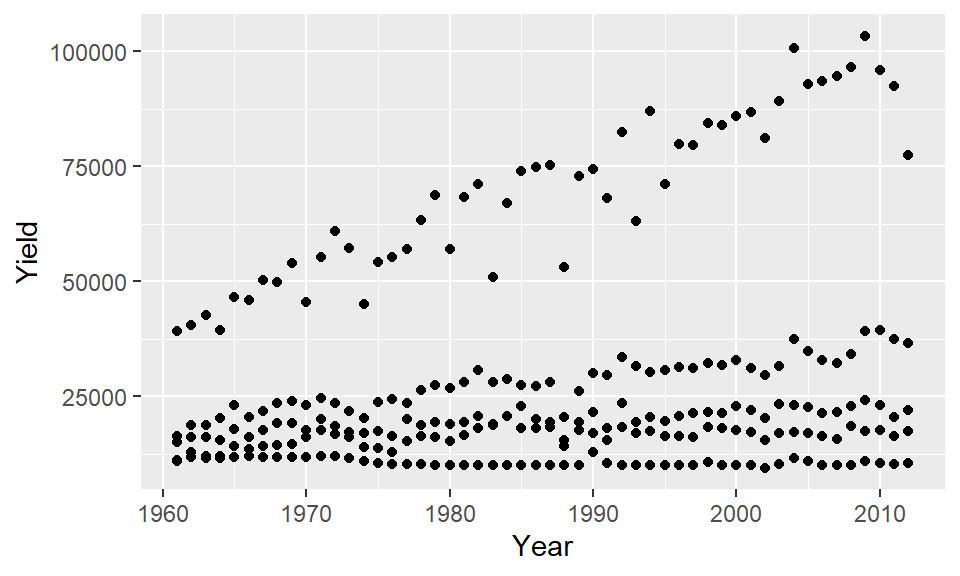
where the function, ggplot(), is passed the data frame name whose contents will be plotted; the aes() function is given data-to-geometry mapping instructions (Year is mapped to the x-axis and Yield is mapped to the y-axis); and geom_line() is the geometry type.
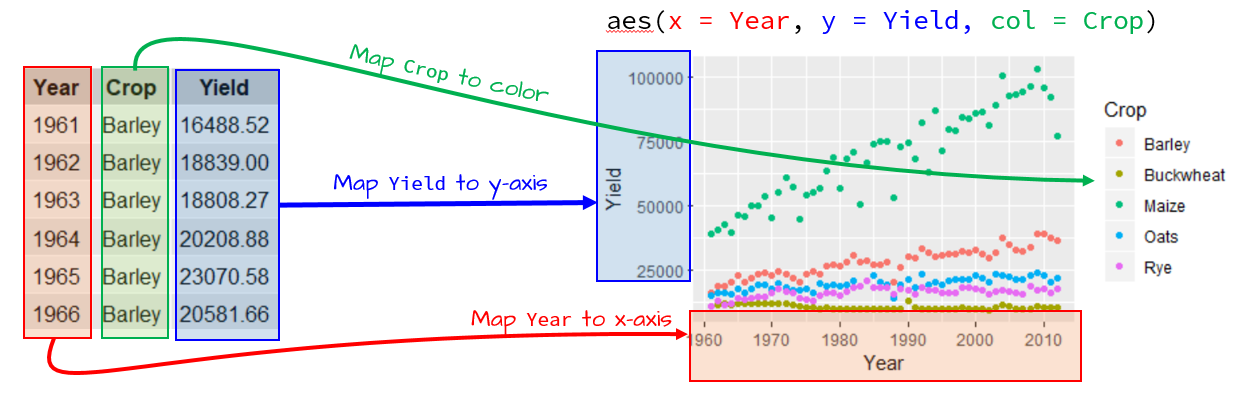
If we wanted to include a third variable such as crop type (Crop) to the map, we would need to map its aesthetics: here we’ll map Crop to the color aesthetic..
ggplot(dat1l , aes(x = Year, y = Yield, color = Crop)) + geom_point()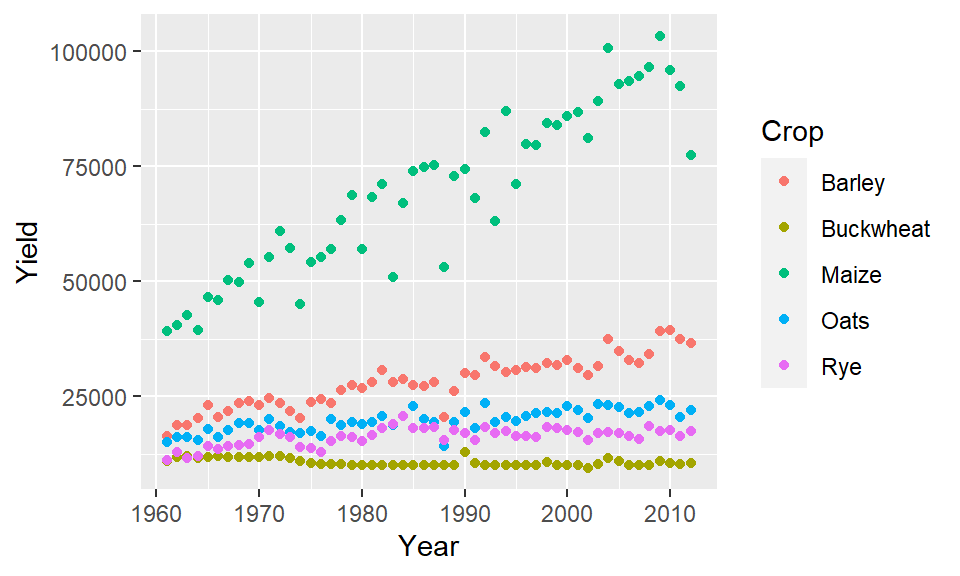
The parameter color acts as a grouping parameter whereby the groups are assigned unique colors.
If we want to plot lines instead of points, simply substitute the geometry type with the geom_line() geometry.
ggplot(dat1l , aes(x = Year, y = Yield, color = Crop)) + geom_line()
Note that the aesthetics are still mapped in the same way with Year mapped to the x coordinate, Yield mapped to the y coordinate and Crop mapped to the geom’s color.
Also, note that the parameters x= and y= can be omitted from the syntax reducing the line of code to:
ggplot(dat1l , aes(Year, Yield, color = Crop)) + geom_line()15.2.1 Common aesthtics for most geoms
x: Position on the x-axisy: Position on the y-axiscolor: Line or point color. If the point symbol has a separate border and fill color, thecoloris assigned to the point symbol’s border.fill: Fill color for tile plots, bar plots, polygons and other filled shapes.size: Point size or line thickness.shape: Point symbol. See Chapter 13 for a list of point symbols.linetype: Line type.group: Grouping variable that isolates lines, boxplots, or barplots. This aesthetic is used if other grouping aesthetics such ascolororlinetypeare not desired. Can also be used in conjunction with other advanced functions such asstat_smooth().
15.3 Geometries
Examples of a few available geometric elements follow.
15.3.1 geom_line
geom_line generates line geometries. We’ll use data from dat1w to generate a simple plot of oat yield as a function of year.
ggplot(dat1w, aes(x = Year, y = Oats)) + geom_line() 
Parameters such as color and linetype can be passed directly to the geom_line() function:
ggplot(dat1w, aes(x = Year, y = Oats)) +
geom_line(linetype = 2, color = "blue", linewidth=0.4) 
Note the difference in how color= is implemented here. It’s no longer mapping a variable’s levels to a range of colors as when it’s called inside of the aes() function, instead, it’s setting the line color to blue.
15.3.2 geom_point
This generates point geometries. This is often used in generating scatterplots. For example, to plot male income (variable B20004013) vs female income (variable B20004007), type:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) 
We modify the point’s transparency by passing the alpha=0.3 parameter to the geom_point function. Other parameters that can be passed to point geoms include color, shape (point symbol type) and size (point size as a fraction).
ggplot(dat2, aes(x = B20004013, y = B20004007)) +
geom_point(color = "red", shape=3 , alpha = 0.3, size=0.6) 
15.3.3 geom_hex
When a bivariate scatter plot has too many overlapping points, it may be helpful to bin the observations into regular hexagons (requires the hexbin package). This provides the number of observations per bin.
ggplot(dat2, aes(x = B20004013, y = B20004007)) +
geom_hex(binwidth = c(1000, 1000)) 
The binwidth argument defines the width and height of each bin in the variables’ axes units.
15.3.4 geom_boxplot
In the following example, a boxplot of Yield is generated for each crop type.
ggplot(dat1l, aes(x = Crop, y = Yield)) + geom_boxplot(fill = "bisque") 
If we want to generate a single boxplot (for example for all yields irrespective of crop type) we need to pass a dummy variable to x=:
ggplot(dat1l, aes(x = "", y = Yield)) +
geom_boxplot(fill = "bisque") + xlab("All crops")
15.3.5 geom_violin
A violin plot is a symmetrical version of a density plot which provides greater detail of a sample’s distribution than a boxplot.
ggplot(dat1l, aes(x = "", y = Yield)) + geom_violin(fill = "bisque") 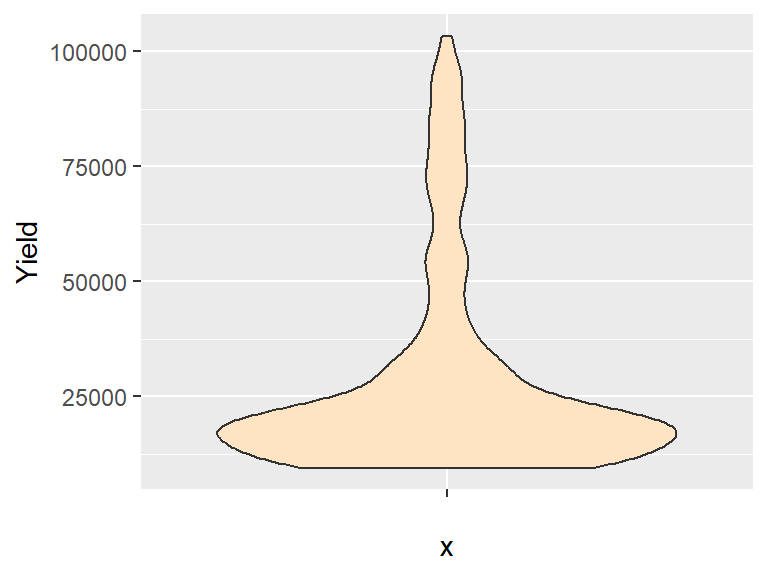
15.3.6 geom_histogram
Histograms can only be plotted for single variables (unless faceting is used) as can be noted by the absence of a y= parameter in aes():
ggplot(dat1w, aes(x = Oats)) + geom_histogram(fill = "grey50") 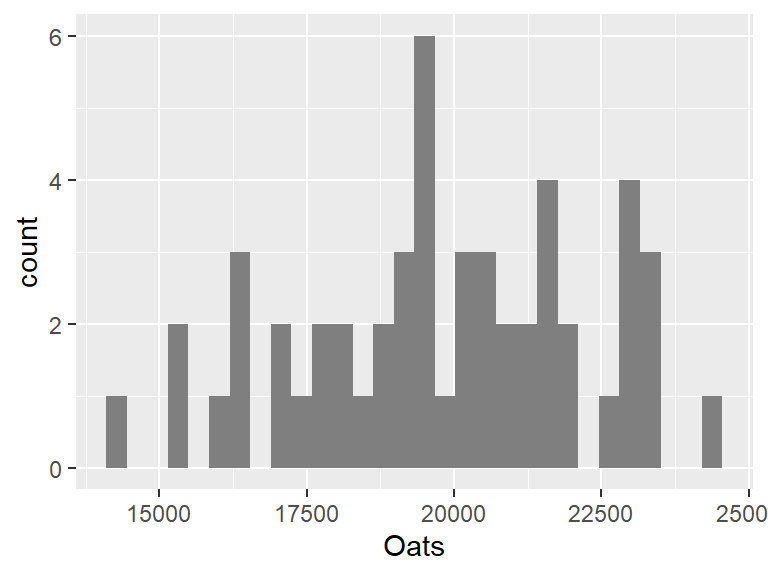
The bin widths can be specified in terms of the value’s units. In our example, the unit is yield of oats (in Hg/Ha). So if we want to generate bin widths that cover 1000 Hg/Ha, we can type,
ggplot(dat1w, aes(x = Oats)) +
geom_histogram(fill = "grey50", binwidth = 1000) 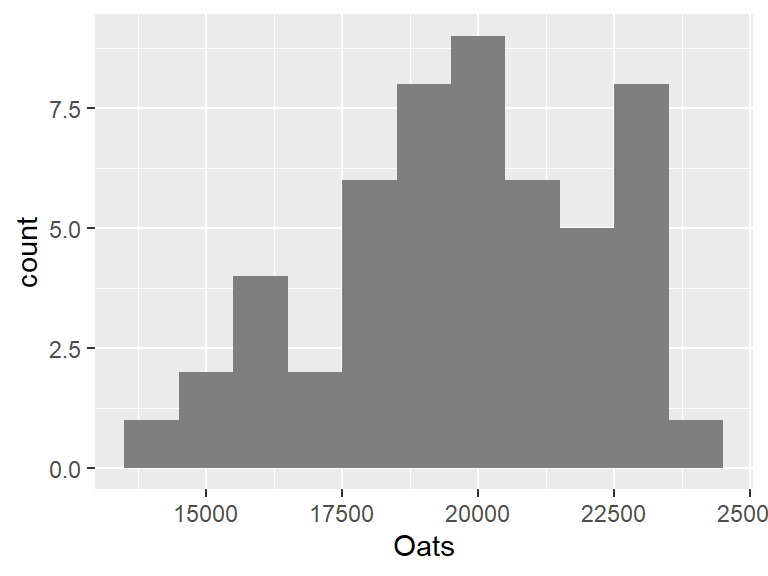
If you want to control the number of bins, use the parameter bins= instead. For example, to set the number of bins to 8, modify the above code chunk as follows:
ggplot(dat1w, aes(x = Oats)) +
geom_histogram(fill = "grey50", bins = 8) 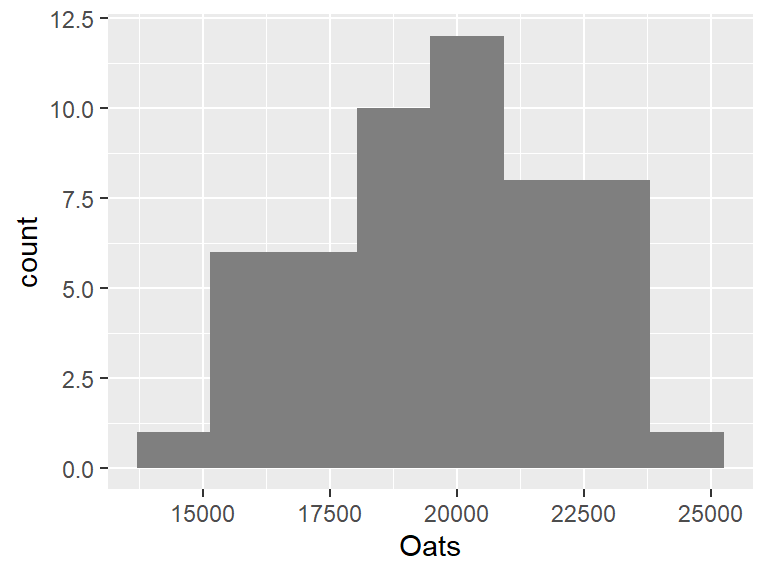
15.3.7 geom_bar
Bar plots are used to summaries the counts of a categorical value. For example, to plot the number of counties in each state (noting that each record in dat2 is assigned a county):
ggplot(dat2, aes(State)) + geom_bar()
To sort the bars by length we need to rearrange the State factor level order based on the number of counties in each state (which is the number of times a state appears in the data frame). We’ll make use of forcats’s fct_infreq function to reorder the State factor levels based on frequency.
library(forcats)
ggplot(dat2, aes(fct_infreq(State,ordered = TRUE))) + geom_bar()
If we want to reverse the order (i.e. plot from smallest number of counties to greatest), wrap the fct_infreq function with fct_rev.
ggplot(dat2, aes(fct_rev(fct_infreq(State,ordered = TRUE)))) + geom_bar()
The geom_bar function can also be used with count values (i.e. variable already summarized by count). First, we’ll summaries the number of counties by state using the dplyr package. This will generate a data frame with just 51 records: one for each of the 50 states and the District of Columbia.
library(dplyr)
dat2.ct <- dat2 %>% group_by(State) %>%
summarize(Counties = n())
head(dat2.ct)# A tibble: 6 × 2
State Counties
<fct> <int>
1 ak 28
2 al 67
3 ar 74
4 az 15
5 ca 57
6 co 62When using summarized data, we must pass the parameter stat="identity" to the geom_bar function. We must also explicitly map the x and y axes geometries. To order the bar heights in ascending or decending order, we can make use of the generic reorder function. This function will be passed two parameters: the variable to be ordered (State), the variable whose values will determine the order (Counties). Note that this differs from the way the reorder function was used in the base plotting chapter where a third argument, median, was passed to the function due to there being more than one value per grouping variable.
ggplot(dat2.ct, aes(x = reorder(State, Counties), y = Counties)) +
geom_bar(stat = "identity")
If you want to reverse the order, simply add a minus sign, -, to the Counties variable.
ggplot(dat2.ct, aes(x = reorder(State, -Counties), y = Counties)) +
geom_bar(stat = "identity")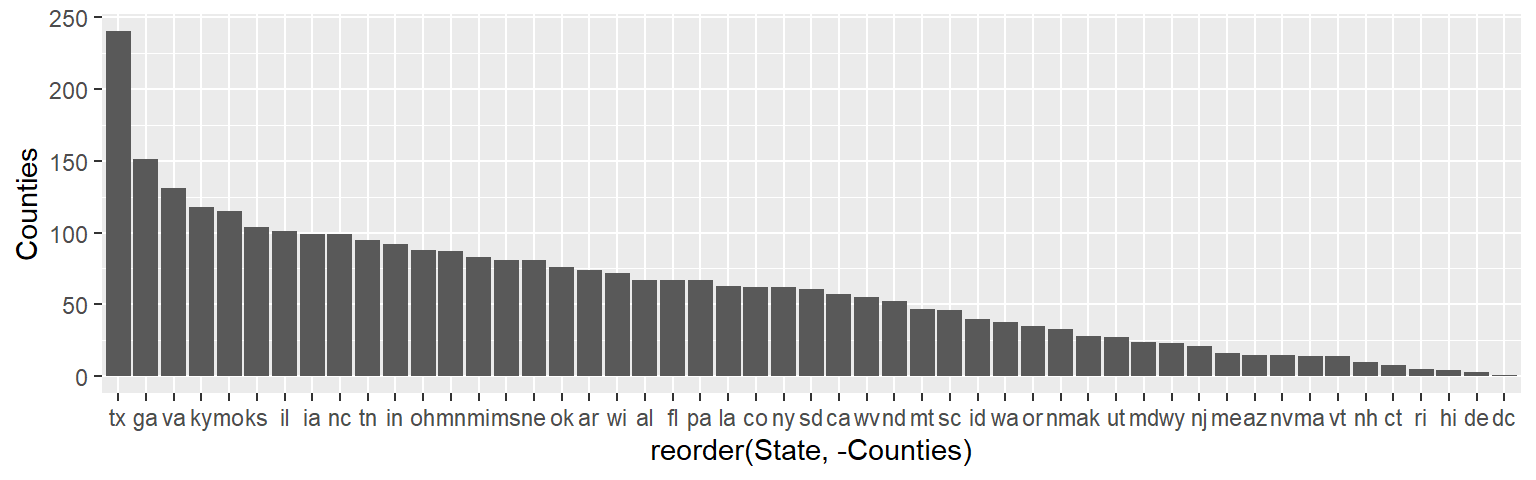
15.3.8 Dot plots
The dot plot is an alternative way to visualize counts as a function of a categorical variable. Instead of mapping State to the x-axis, we’ll map it to the y-axis.
ggplot(dat2.ct , aes(x = Counties, y = State)) + geom_point()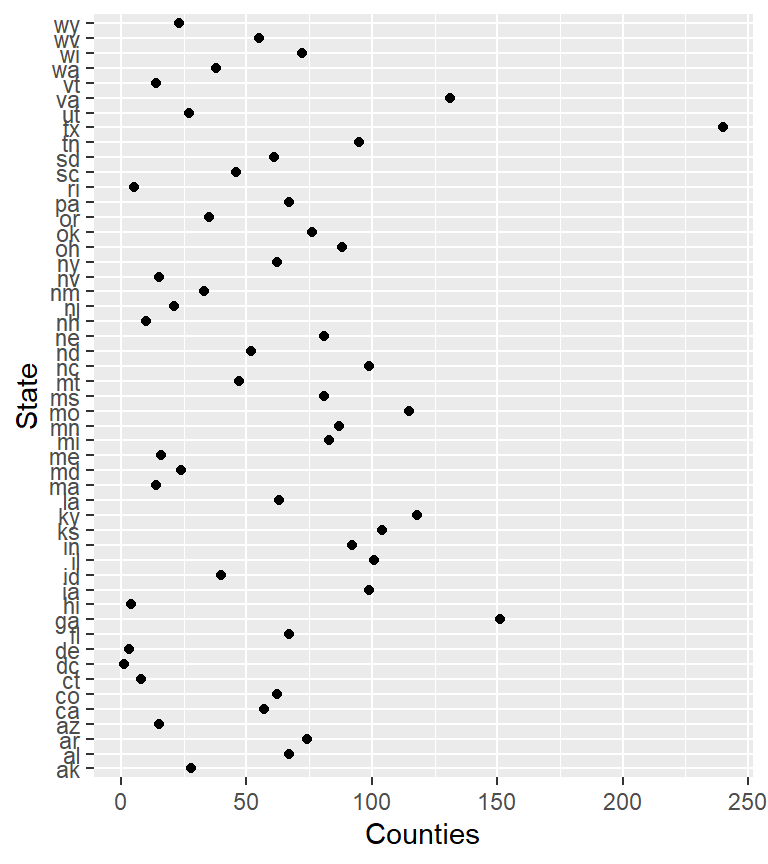
Dot plot graphics benefit from sorting–more so then bar plots.
ggplot(dat2.ct , aes(x = Counties, y = reorder(State, Counties))) +
geom_point() + ylab("States")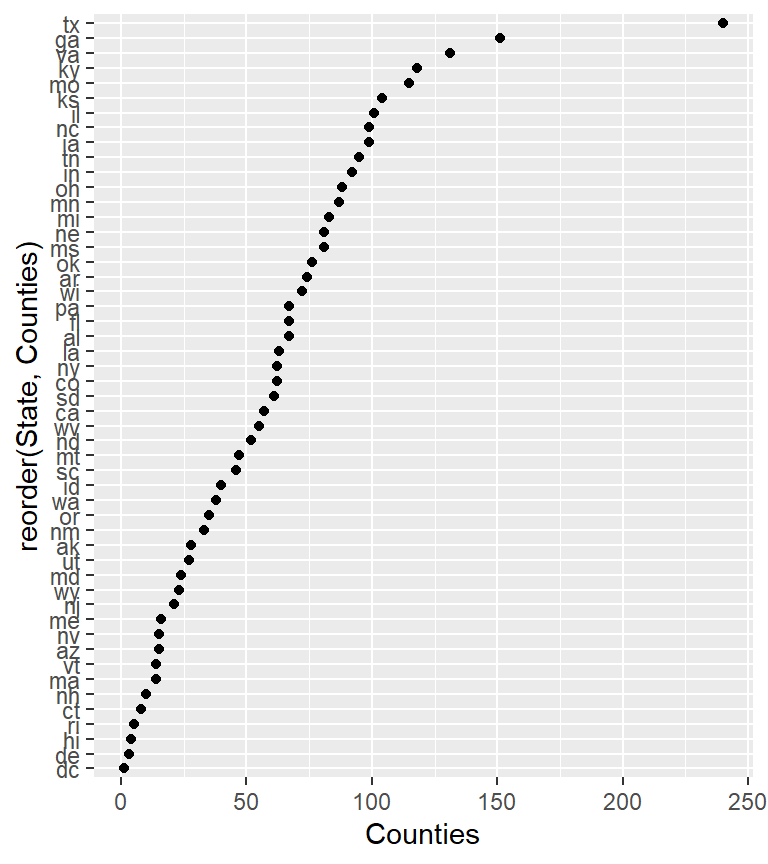
You can add a horizontal line segment connecting the points to some location along the x-axis using geom_segment(). For example, to connect the points to x=0 type,
ggplot(dat2.ct , aes(x = Counties, y = reorder(State, Counties))) +
geom_point() + ylab("States") +
geom_segment(aes(xend = 0, yend = State), col = "grey30")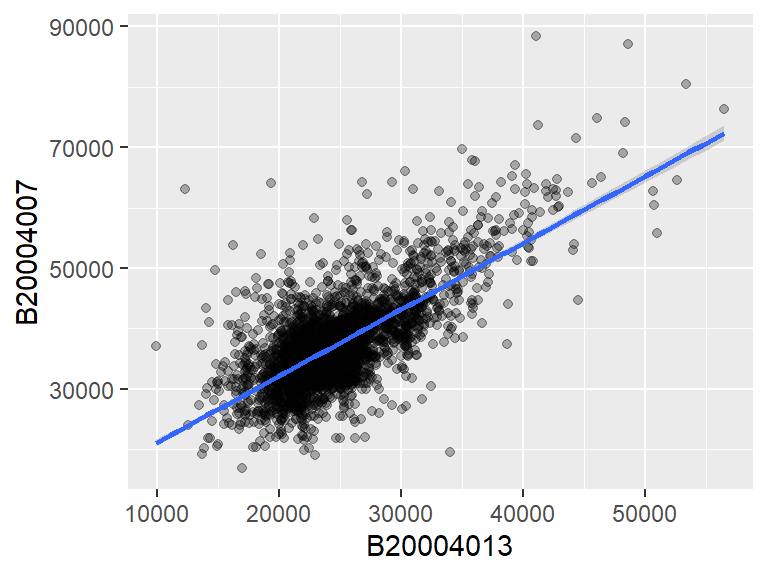
15.3.9 Tile plots (heat maps)
You can create heat maps by tiling the data where color represents a third variable’s value. This typically requires three variables: two that define a rectangular grid—either categorical or evenly spaced continuous values—and a third, the continuous variable, that determines the color of each tile.
For example, a tile plot can illustrate median income (for all sexes) as a function of education level and region. Here, the Region will be mapped to the x-axis, the Level to the y-axis and the median Income to the fill color aesthetic.
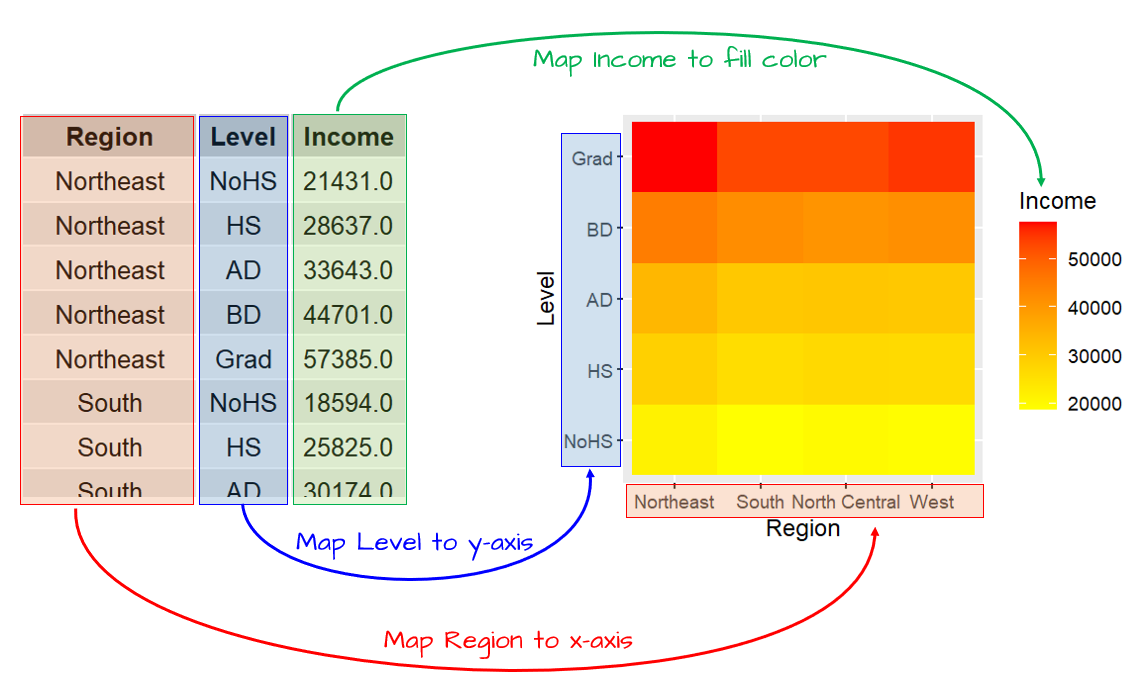
But first, we summarize the data to generate a three variable dataset.
dat2c.med <- dat2c %>%
filter(Level != "All") %>%
group_by(Region, Level) %>%
summarise(Income = median(All))
head(dat2c.med)# A tibble: 6 × 3
# Groups: Region [2]
Region Level Income
<fct> <fct> <dbl>
1 Northeast NoHS 21431
2 Northeast HS 28637
3 Northeast AD 33643
4 Northeast BD 44701
5 Northeast Grad 57385
6 South NoHS 18594Next, we generate the plot.
ggplot(dat2c.med, aes(x = Region, y = Level, fill = Income)) + geom_tile() +
scale_fill_gradient(low = "yellow", high = "red")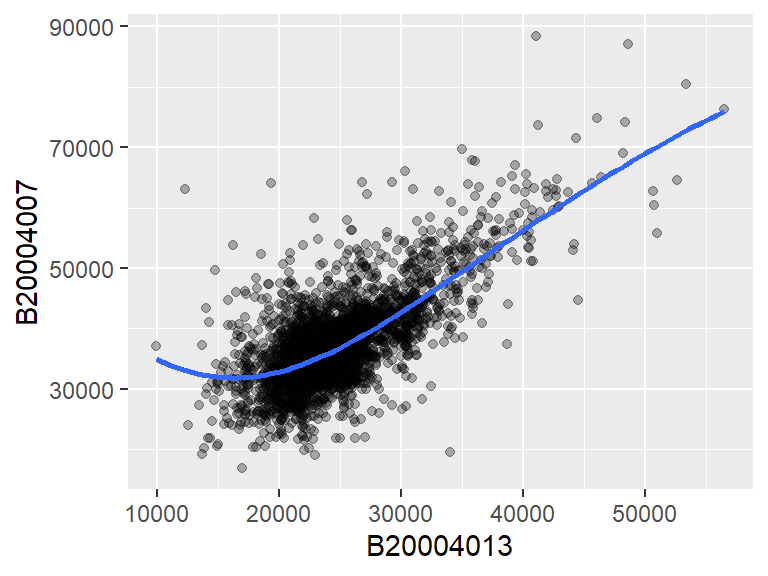
The above example adopts a continuous color scheme where yellow is assigned to the smaller values and red to the higher values. Additional color options are presented later in this chapter.
15.3.10 Combining geometries
Geometries can be layered. For example, to overlay a linear regression line to the data we can add the stat_smooth layer:
ggplot(dat2, aes(x = B20004013, y = B20004007)) +
geom_point(alpha = 0.3) +
stat_smooth(method = "lm")
The stat_smooth can be used to fit other lines such as a loess:
ggplot(dat2, aes(x = B20004013, y = B20004007)) +
geom_point(alpha = 0.3) +
stat_smooth(method = "loess")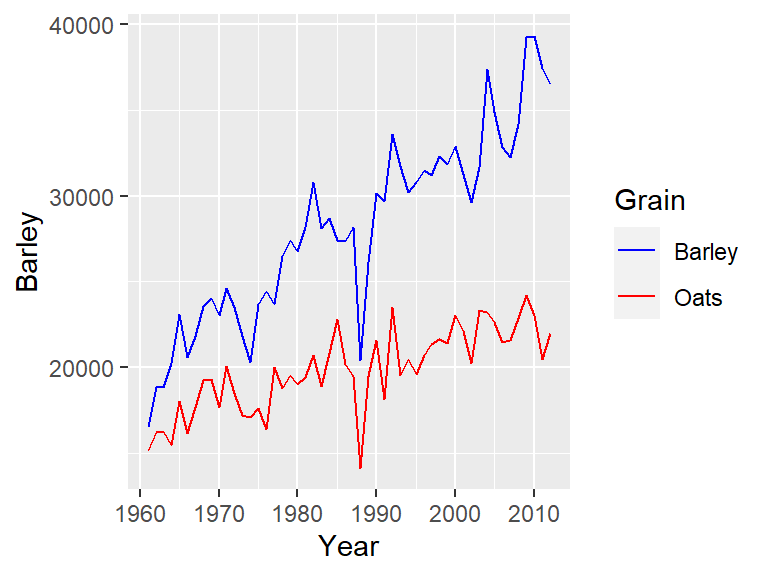
The confidence interval can be removed from the smooth geometry by specifying se = FALSE.
ggplot(dat2, aes(x = B20004013, y = B20004007)) +
geom_point(alpha = 0.3) +
stat_smooth(method = "loess", se = FALSE)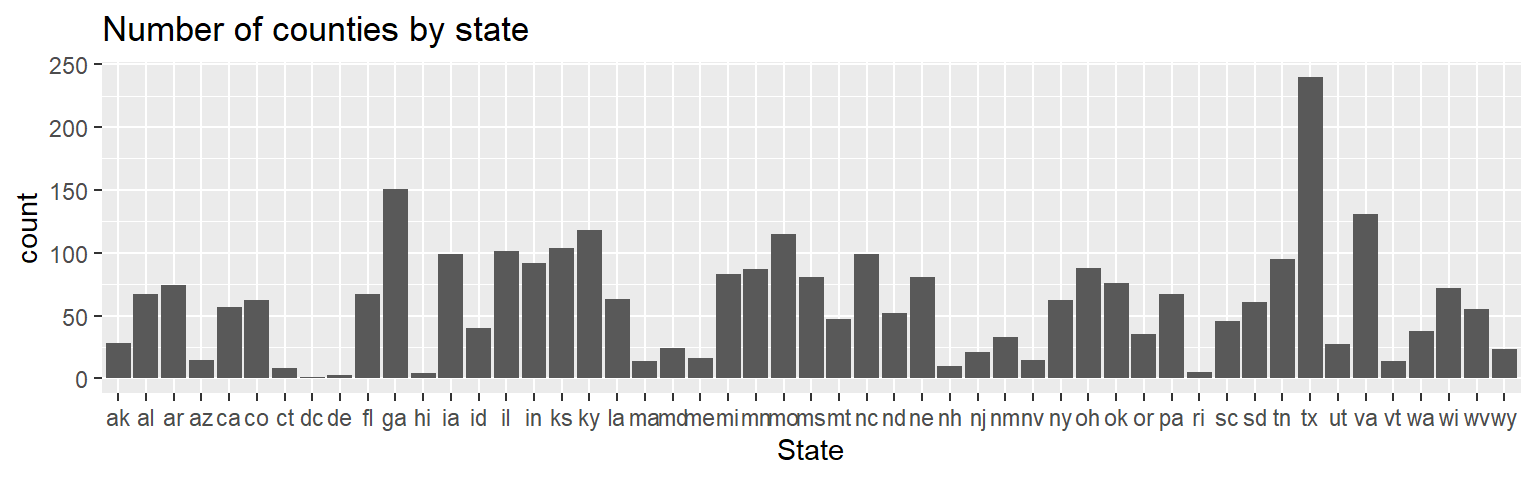
15.3.11 Combining datasets
You can plot multiple datasets (i.e. from separate dataframes) on the same ggplot2 canvas by assigning each geom its own dataset and aesthetics. In the following example, we create two separate data frames: one for barley and another for oats. Each dataset is referenced in a separate geom_line() call.
grain1 <- select(dat1w, Year, Barley)
grain2 <- select(dat1w, Year, Oats)
ggplot() +
geom_line(data = grain1, aes(Year, Barley), color = "blue", show.legend = TRUE) +
geom_line(data = grain2, aes(Year, Oats), color = "red", show.legend = TRUE) 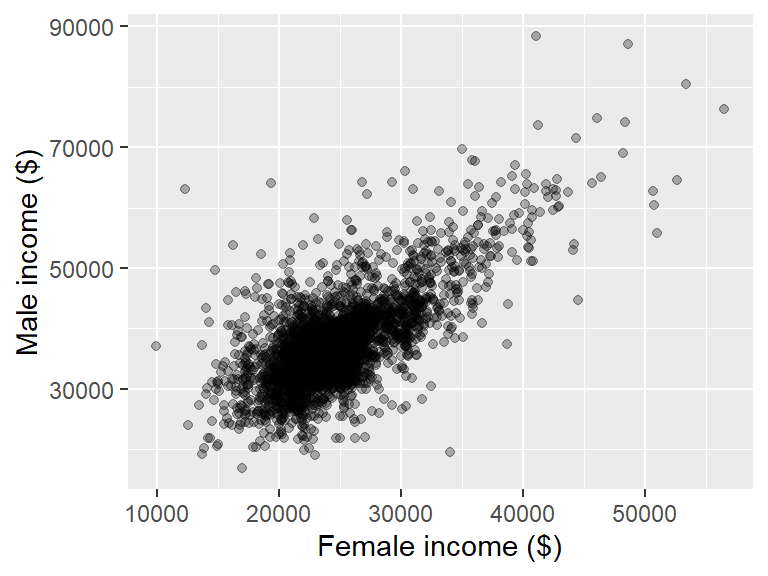
Notice that a legend is not automatically generated since the aesthetics are not specified within ggplot(). To include a legend, we must assign a character string to the color argument inside aes(). We then use scale_color_manual() to map these values to specific colors.
ggplot() +
geom_line(data = grain1, aes(Year, Barley, color = "Barley")) +
geom_line(data = grain2, aes(Year, Oats, color = "Oats")) +
scale_color_manual(name = "Grain", values = c("Barley" = "blue", "Oats" = "red"))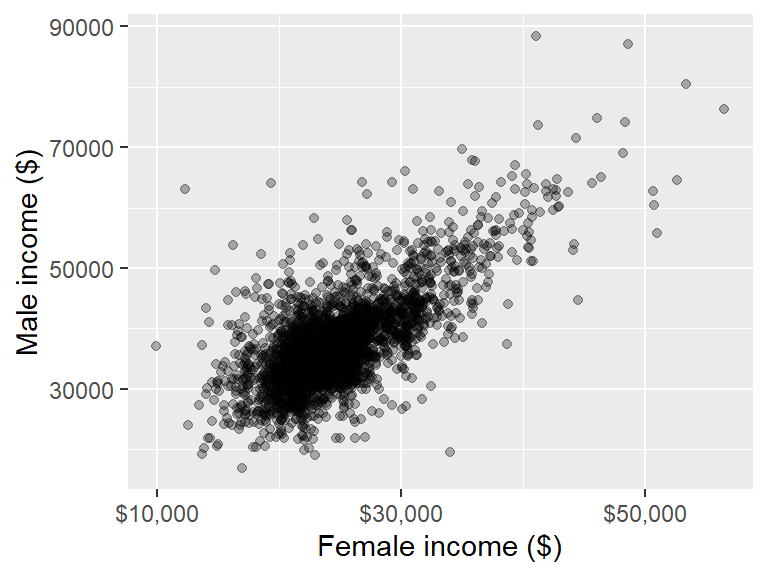
Here, we remove the color="blue" and color="red" arguments from geom_line() and instead specify the color aesthetic within aes().
In this example, barley and oats are stored in separate data frames to illustrate how to plot data from multiple sources. However, it’s generally best to combine variables into a single data frame whenever possible and use aesthetics like color to distinguish categories. This approach simplifies the code and improves readability. The same plot can be generated more efficiently as follows:
grains <- filter(dat1l, Crop %in% c("Barley", "Oats"))
ggplot(grains, aes(Year, Yield, color = Crop)) +
geom_line() +
scale_color_manual(name = "Grain", values = c("Barley" = "blue", "Oats" = "red"))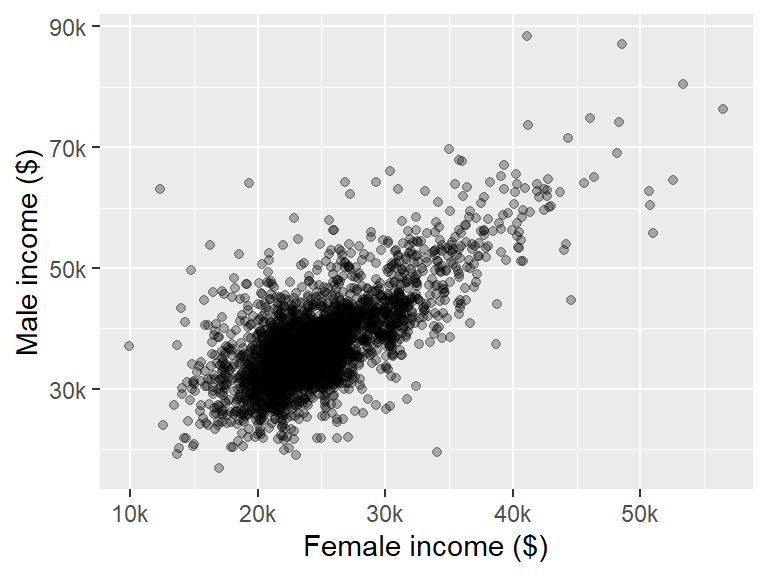
15.4 Tweaking a ggplot2 graph
15.4.1 Plot title
You can add a plot title using the ggtitle function.
ggplot(dat2, aes(State)) + geom_bar() + ggtitle("Number of counties by state")
15.4.2 Axes titles
Axes titles can be explicitly defined using the xlab() and ylab() functions.
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)")
To remove axis labels, simply pass NULL to the functions as in xlab(NULL) and ylab(NULL).
15.4.3 Axes labels
You can customize an axis’ label elements. If you are mapping continuous values along the x and y axes, use the scale_x_continuous() and scale_y_continuous() functions. For example, to specify where to place the tics and the accompanying labels, type:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(breaks = c(10000, 30000, 50000),
labels = c("$10,000", "$30,000", "$50,000"))
If you want to change the label formats whereby the numbers are truncated to a thousandth of their original value, you can make use of label_number() from the scales package:
ggplot(dat2, aes(x=B20004013, y=B20004007)) + geom_point(alpha=0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(labels=scales::label_number(suffix="k",
scale=0.001)) +
scale_y_continuous(labels=scales::label_number(suffix="k",
scale=0.001))
The suffix argument adds "k" to the end of the number and the scale argument rescales the values by 0.001.
The scales package also has a label_comma() function that will add commas to large numbers:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(labels = scales::label_comma()) +
scale_y_continuous(labels = scales::label_comma())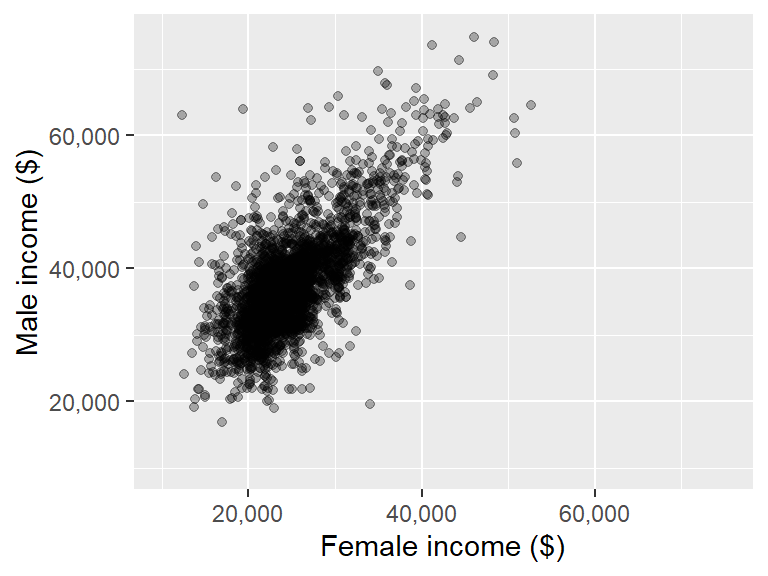
You can rotate axes labels using the theme function.
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) 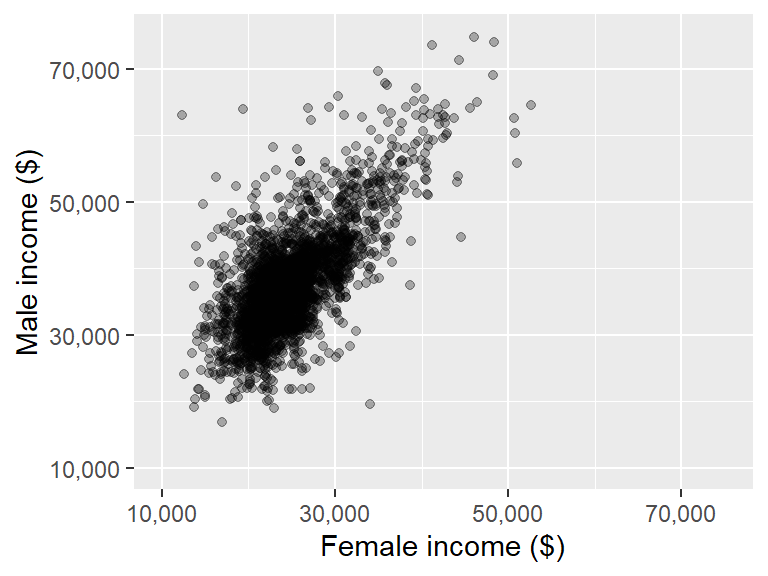
The hjust argument justifies the values horizontally. Its value ranges from 0 to 1 where 0 is completely left-justified and 1 is completely right-justified. Note that the justification is relative to the text’s orientation and not to the axis. So it may be best to first rotate the label values and then to adjust justification based on the plot’s look as needed.
If you want the label values rotated 90° you might also need to justify vertically (relative to the text’s orientation) using the vjust argument where 0 is completely top-justified and 1 is completely bottom-justified.
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0)) 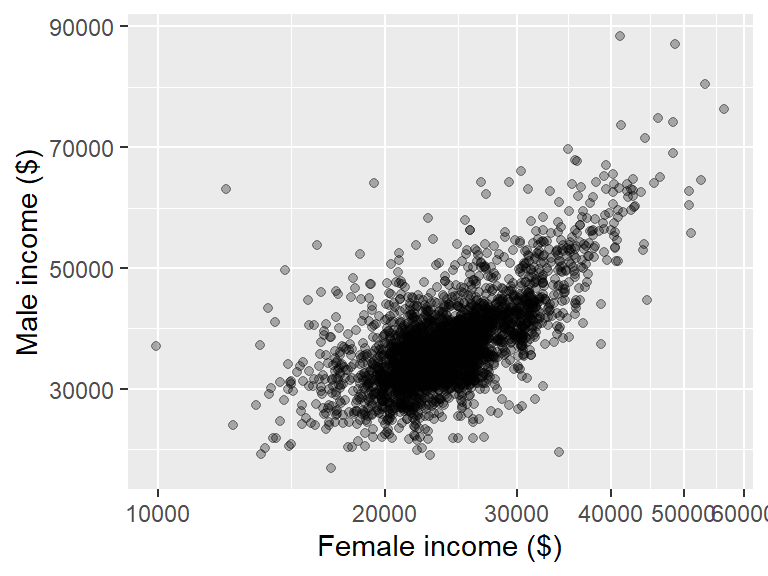
15.4.4 Axes limits
The axis range can be set using xlim() and ylim().
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
xlim(10000, 75000) + ylim(10000, 75000)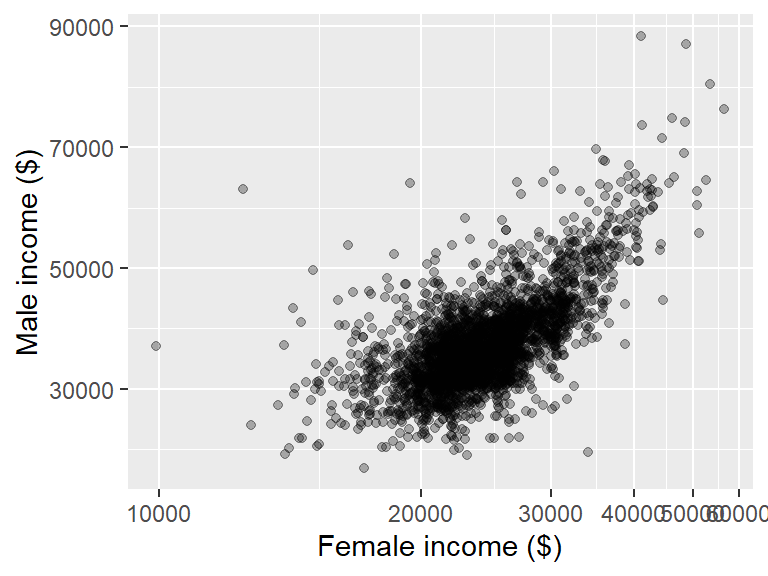
However, if you are calling the scale_x_continuous() and scale_y_continuous() functions, you do not want to use xlim and ylim instead, you should add the limit= argument to the aforementioned functions. For example,
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(limit = c(10000, 75000),
labels = scales::label_comma()) +
scale_y_continuous(limit = c(10000, 75000),
labels = scales::label_comma())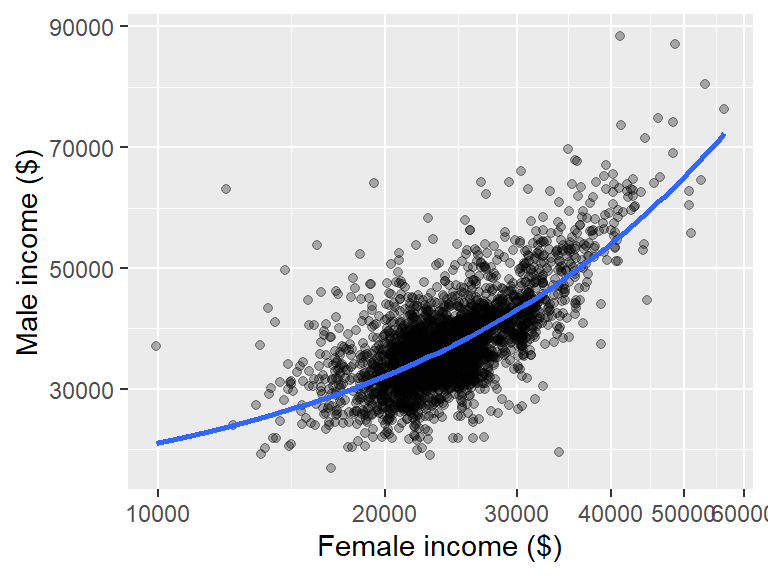
15.4.5 Axes breaks
You can explicitly define the breaks with the breaks argument. Continuing with the last example, we get:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(limit = c(10000, 75000),
labels = scales::label_comma(),
breaks = c(10000, 30000, 50000, 70000)) +
scale_y_continuous(limit = c(10000, 75000),
labels = scales::label_comma(),
breaks = c(10000, 30000, 50000, 70000))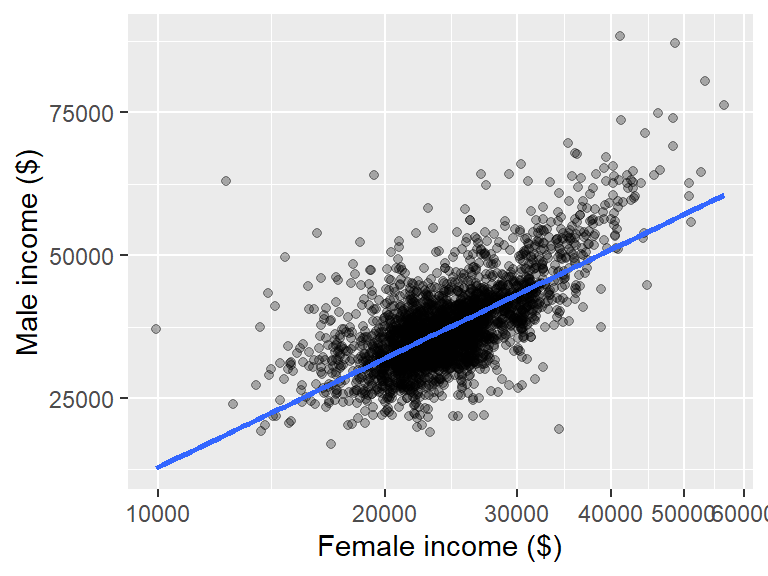
Note that the breaks argument can be used in conjunction with other arguments (as shown in this example), or by itself.
15.4.6 Axes and data transformations
If you wish to apply a non-linear transformation to either axes (while preserving the untransformed axis values) add the coord_trans() function as follows:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
coord_trans(x = "log")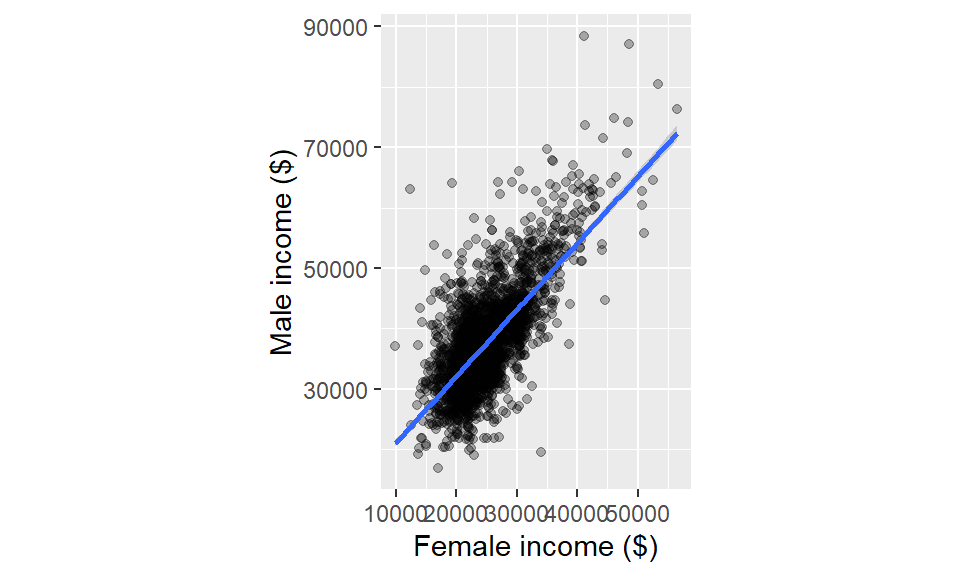
You can also transform the y-axis by specifying the parameter y=. The log transformation defaults to the natural log. For a log base 10, use "log10" instead. For a square root transformation, use "sqrt". For the inverse use "reciprocal".
Advanced transformations can be called via the scales package. For example, to implement the box-cox transformation (with a power of -0.3), type:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
coord_trans(x = scales::boxcox_trans(-0.3))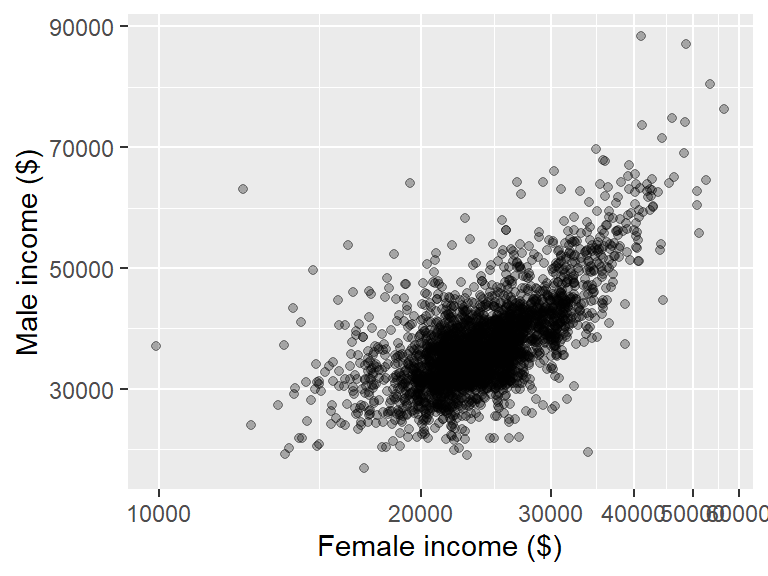
If the data contains zeros or negative values, some transformations, such as the logarithm, may fail. When the goal is to apply a non-linear scale to the axes without a strong concern for interpretability, a hybrid transformation function like pseudo_log_trans() from the scales package can be used.
This function provides a smooth transition between a linear scale for small values (including negatives) and a logarithmic scale for larger values. It takes a key argument, sigma, which determines the threshold along the value range where the transformation shifts from linear to logarithmic behavior and thus affects the speed of the transition from linear to logarithmic scaling,
For example, to transform the x-axis (where we center income around its median to generate negative values for this demonstration) and setting the transition threshold to 5000, use the following:
ggplot(dat2, aes(x = (B20004013 - 23000), y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(trans = scales::pseudo_log_trans(sigma = 5000))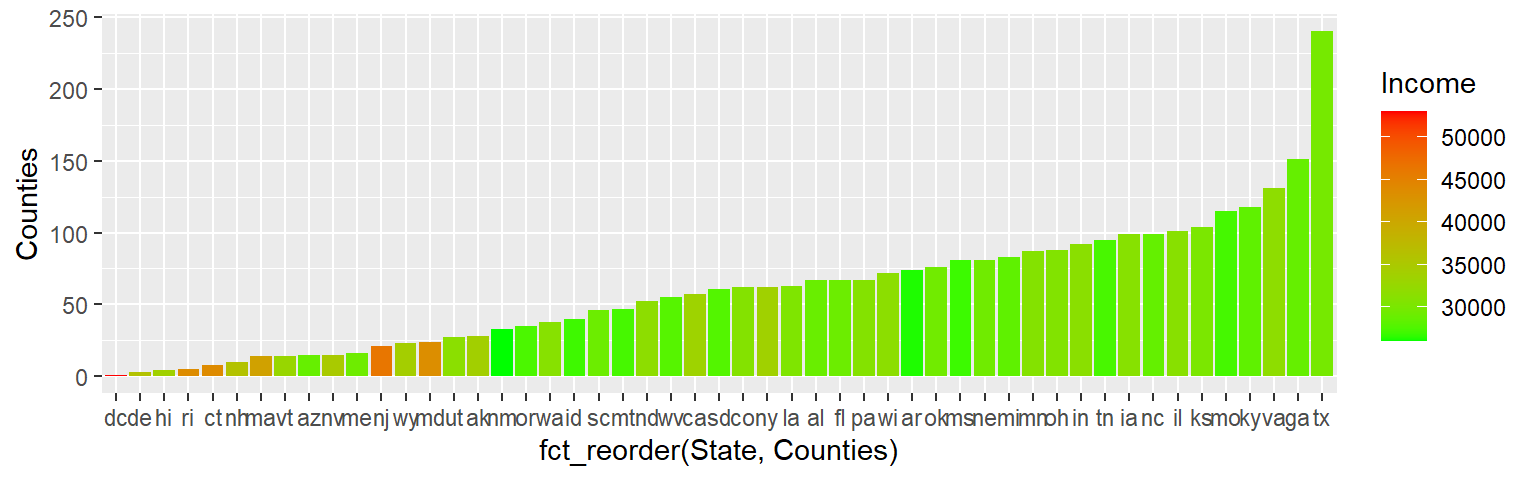
Note that when the data contains both negative and positive values, setting sigma close to 0 causes the transformation to rapidly shift to a symmetric log scale thus pulling negative and positive values apart symmetrically. This occurs because smaller sigma values accelerate the transition from a linear to a logarithmic scale.
For example, setting sigma = 1000 demonstrates this effect, as shown in the following example
ggplot(dat2, aes(x = (B20004013 - 23000), y = B20004007)) + geom_point(alpha = 0.3) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(trans = scales::pseudo_log_trans(sigma = 1000))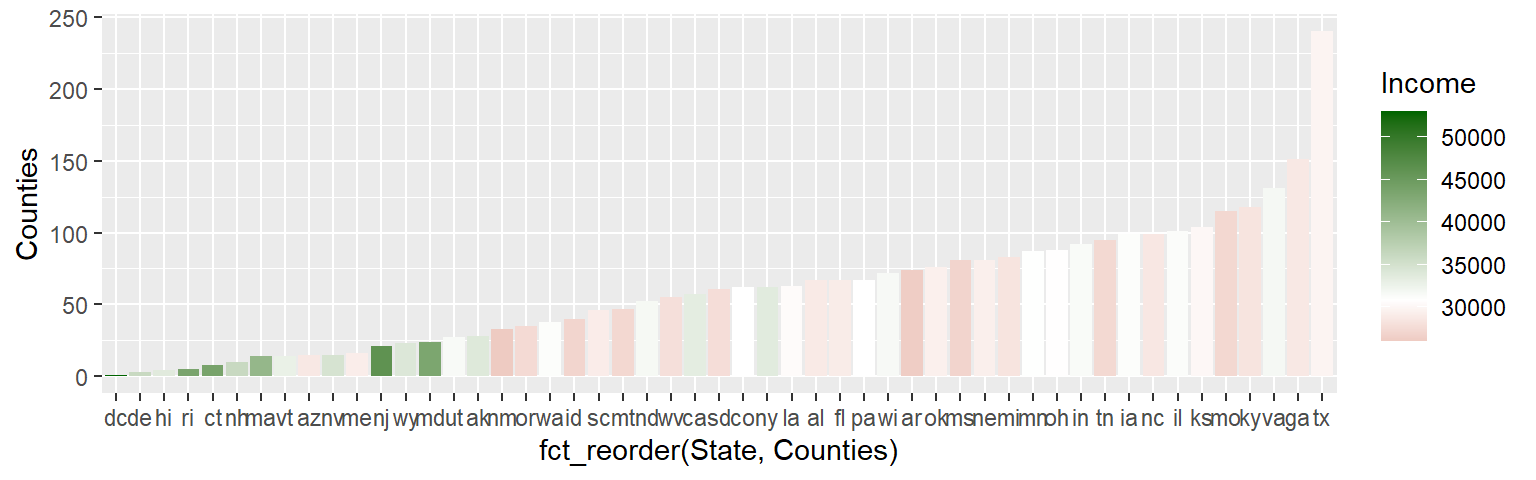
Note that any statistical geom (such as the smooth fit) will be applied to the un-transformed data. So a linear model may end up looking non-linear after an axis transformation:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
stat_smooth(method = "lm", se = FALSE) +
xlab("Female income ($)") + ylab("Male income ($)") +
coord_trans(x = "log")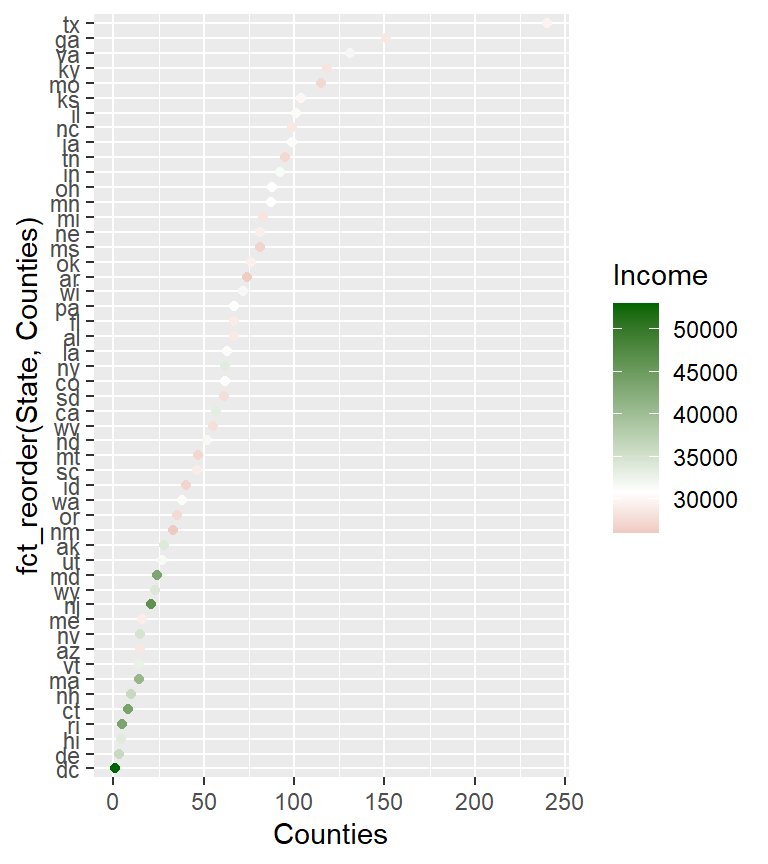
If a linear fit is to be applied to the transformed data, a better alternative is to transform the values instead of the axes. The transformation can be done on the original data or it can be implemented in ggplot using the scale_x_continuous and scale_y_continuous functions.
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
stat_smooth(method = "lm", se = FALSE) +
xlab("Female income ($)") + ylab("Male income ($)") +
scale_x_continuous(trans = "log", breaks = seq(10000,60000,10000))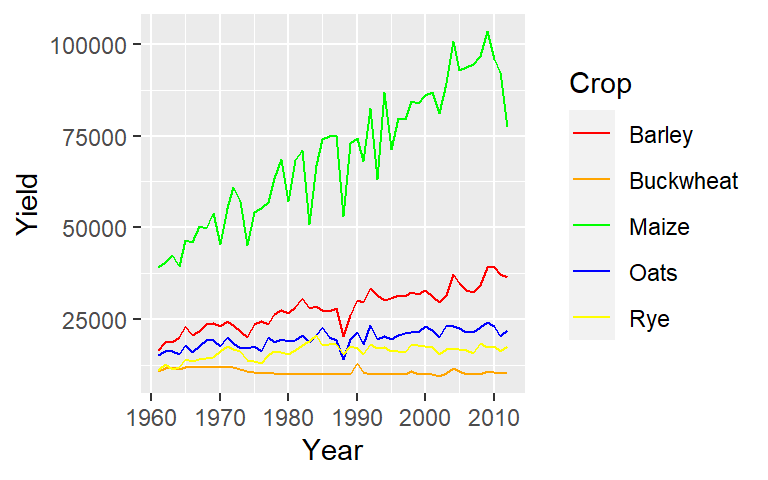
The scale_x_continuous and scale_y_continuous functions will accept scales transformation parameters–e.g. scale_x_continuous(trans = scales::boxcox_trans(-0.3)). Note that the parameter breaks is not required but is used here to highlight the transformed nature of the axis.
15.4.7 Aspect ratio
You can impose an aspect ratio to your plot using the coord_equal() function. For example, to set the axes units equal (in length) to one another set ratio=1:
ggplot(dat2, aes(x = B20004013, y = B20004007)) + geom_point(alpha = 0.3) +
stat_smooth(method = "lm") +
xlab("Female income ($)") + ylab("Male income ($)") +
coord_equal(ratio = 1)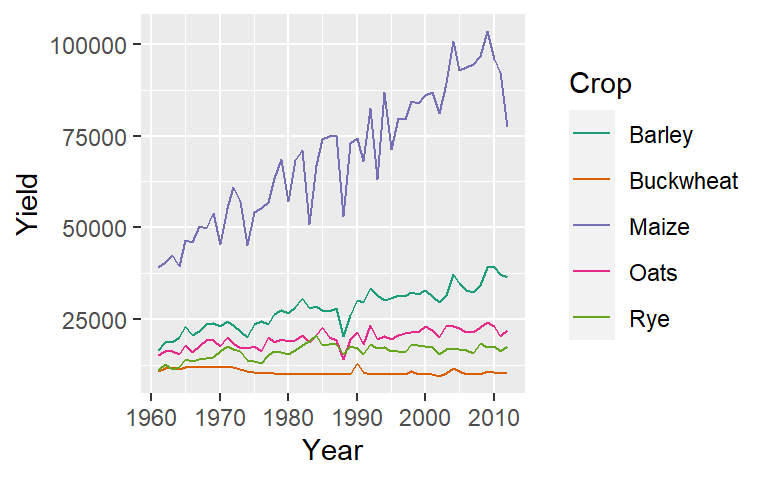
15.4.8 Adding mathematical symbols to a plot
You can embed math symbols using plotmath’s mathematical expressions by wrapping these expressions in an expression() function. For example,
ggplot(dat2, aes(x = B20004013^0.333, y = sqrt(B20004007))) + geom_point(alpha = 0.3) +
xlab( expression( ("Female income") ^ frac(1,3) ) ) +
ylab( expression( sqrt("Male income") ) )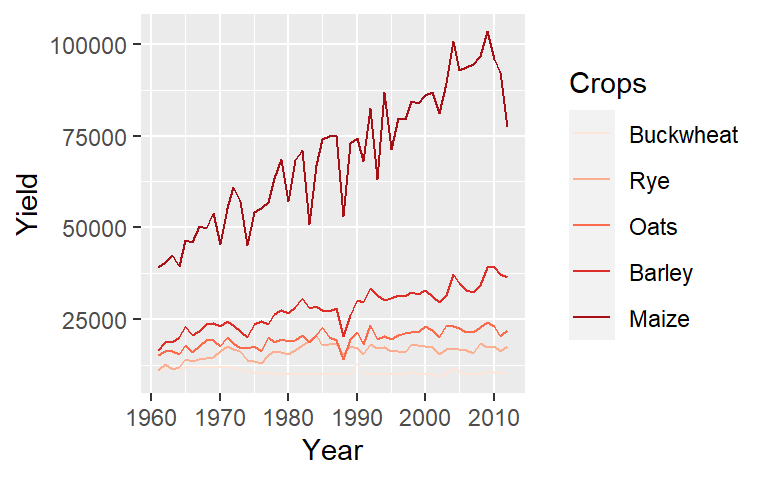
To view the full list of mathematical expressions, type ?plotmath at a command prompt.
15.5 Colors
You can customize geom colors using two types of color scales: one for continuous values and another for categorical (discrete) values. Pay attention to the slight variation in function names, especially when specifying fill colors versus regular color aesthetics.
- fill applies to filled objects like bars (
geom_bar()), boxplots (geom_boxplot()), or tiles (geom_tile()). - color controls the outline or stroke color of shapes and the color of points and lines (e.g.,
geom_point(),geom_line()).
15.5.0.1 Continuous color scales
scale_color_gradient(): Applies a two-color gradient for mapped color aesthetics (e.g., from low to high values).scale_fill_gradient(): Applies a two-color gradient for mapped fill aesthetics (used for filled objects like bars and tiles).scale_color_gradient2(): Applies a divergent color gradient for mapped color aesthetics using three colors for low, mid, and high values. The mid-color is associated with a defined midpoint.scale_fill_gradient2(): Applies a divergent color gradient for mapped fill aesthetics using three colors for low, mid, and high values. The mid-color is associated with a defined midpoint.scale_color_brewer(): Applies a sequential or divergent color scale for mapped color aesthetics using pre-defined color palettes from theRColorBrewerpackage designed for perceptually uniform color scales.scale_fill_brewer(): Applies a sequential or divergent color scale for mapped fill aesthetics using pre-defined color palettes from theRColorBrewerpackage designed for perceptually uniform color scales.
15.5.0.2 Categorical color scales
scale_color_hue(): Assigns distinct hues to different categorical groups mapped to color aesthetics.scale_fill_hue(): Assigns distinct hues to different categorical groups mapped to fill aesthetics.scale_color_manual(): Allows manual specification of colors to different categorical groups mapped to color aesthetics.scale_fill_manual(): Allows manual specification of colors to different categorical groups mapped to fill aesthetics.scale_color_brewer(): UsesRColorBrewercategorical palettes, designed for clear and distinct color separation.scale_color_brewer(): UsesRColorBrewercategorical palettes, designed for clear and distinct color separation.
15.5.1 Continuous color schemes
Continuous color schemes can be classified as either sequential or divergent:
Sequential color schemes transition from a light hue to a darker hue as values increase, typically maintaining the same hue family (e.g., light green to dark green).
Divergent color schemes use two distinct hues that gradually shift from dark to light, converging at a mid-value. This midpoint often represents a meaningful reference, such as zero or an average.
15.5.1.1 Sequential color scheme
The RColorBrewer package provides a collection of predefined color palettes that can be used in ggplot2. These palettes are directly accessible within ggplot2, so you do not need to install RColorBrewer separately to use them.
However, if you want to view the list of available palettes, you will need to install the RColorBrewer package.
The following code snippet displays the available sequential color palettes:
RColorBrewer::display.brewer.all(type = "seq")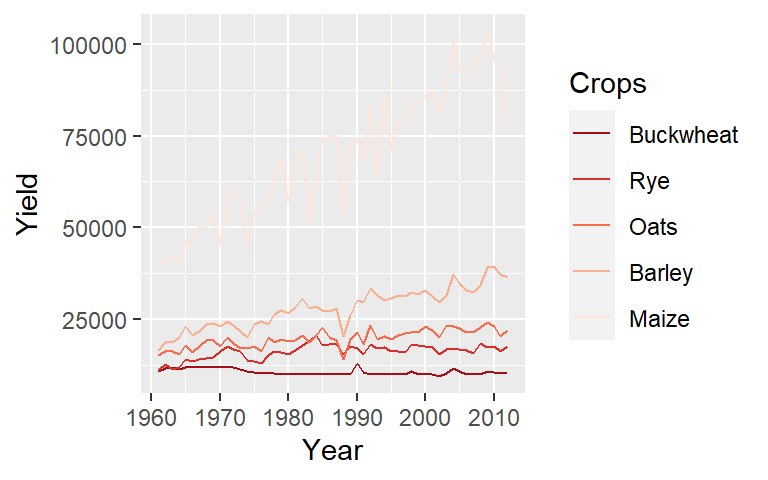
Let’s assume that there is an implied order to the crop types. For example, we’ll reorder the crop types based on their median yield (this creates an ordered factor from the Crop variable). We can then assign Brewer’s Reds palette to the Crop aesthetic.
ggplot(dat1l, aes(Year, Yield, col = reorder(Crop, Yield, median))) +
geom_line() +
guides(color = guide_legend(reverse = TRUE)) +
scale_color_brewer(palette = "Reds", name = "Crops") 
Note that we added a guides() function to reverse the legend element order. This function is not needed to generate the sequential colors. We also renamed the legend header via the name = "Crops" argument in scale_color_brewer().
If you want to reverse the color scheme, set direction = -1 in the scale_color_brewer() function.
When applying a sequential color scheme to points and lines, the palette’s lighter hue may blend with the plot’s default grey background. One solution is to slightly darken the background color such as grey87,
ggplot(dat1l, aes(Year, Yield, col = reorder(Crop, Yield, median))) +
geom_line() +
guides(color = guide_legend(reverse = TRUE)) +
scale_color_brewer(palette = "Reds", name = "Crops") +
theme(panel.background = element_rect(fill = 'grey87', color = 'white'))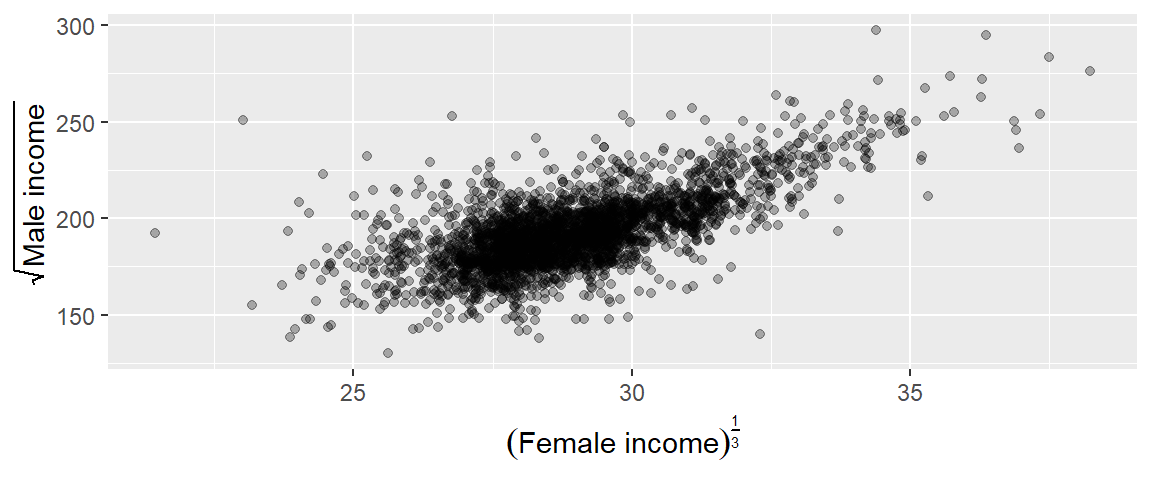
Alternatively, you can go with a black and white themed background.
ggplot(dat1l, aes(Year, Yield, col = reorder(Crop, Yield, median))) +
geom_line() +
guides(color = guide_legend(reverse = TRUE)) +
scale_color_brewer(palette = "Reds", name= "Crops") +
theme_bw()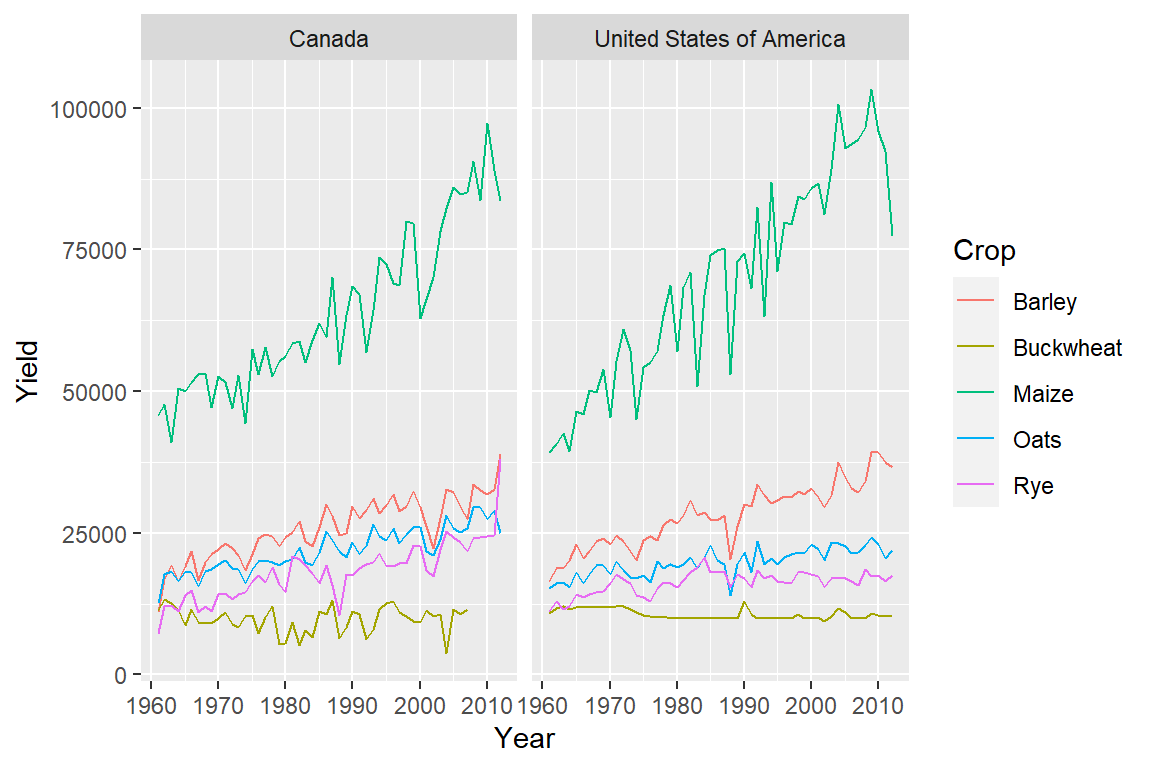
If a variable is mapped to the fill aesthetic, use the corresponding ..._fill_... function.
For example, to color the boxplots with shades of red based on the median yield for each crop, use:
ggplot(dat1l, aes(reorder(Crop, Yield, median), Yield, fill = reorder(Crop, Yield, median))) +
geom_boxplot() +
guides(fill = guide_legend(reverse = TRUE)) +
scale_fill_brewer(palette = "Reds", name = "Crops") 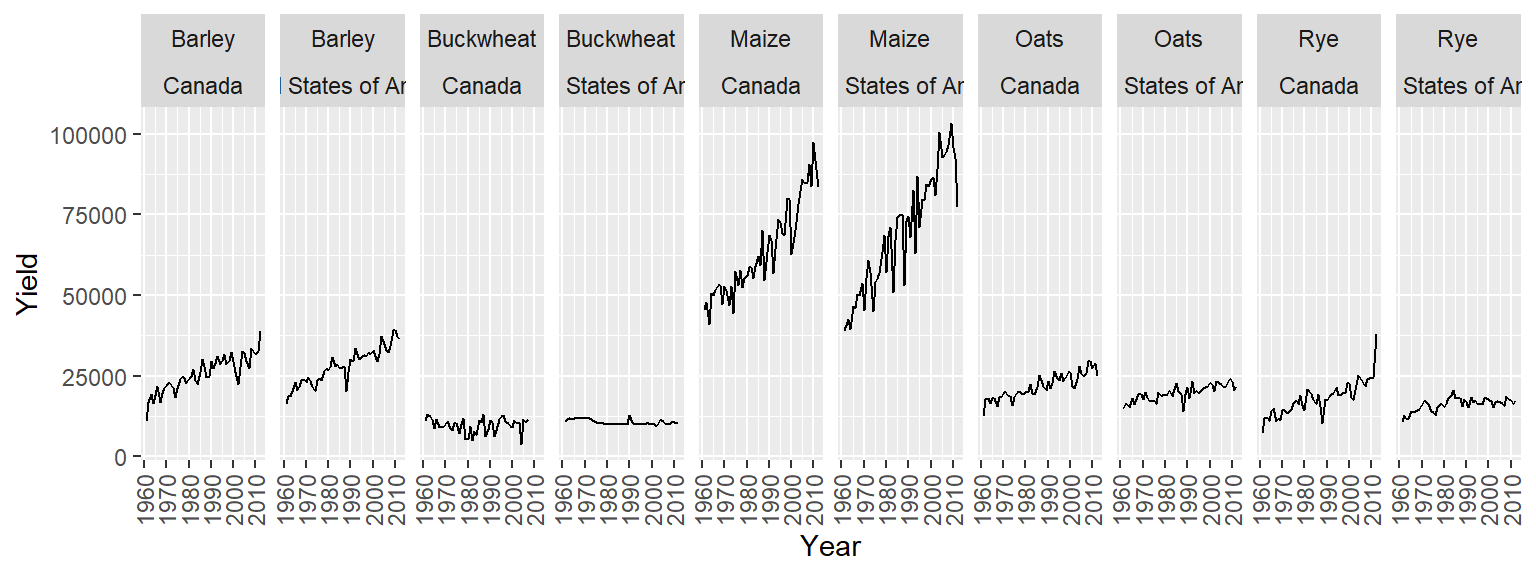
NOTE: This example demonstrates the use of the fill aesthetic. However, mapping the same variable to the fill aesthetic multiple times is redundant and should generally be avoided for clarity and efficiency.
The scale_..._brewer() functions can only be applied to discrete/binned data. If you are applying a color scheme to a continuous (non-binned) variable, you should use one of the scale_..._gradient() functions, instead. For example, to apply a bisque to darkred gradient to the Income variable from an earlier tiled plot, type:
ggplot(dat2c.med, aes(x = Region, y = Level, fill = Income)) + geom_tile() +
scale_fill_gradient(low = "bisque", high = "darkred")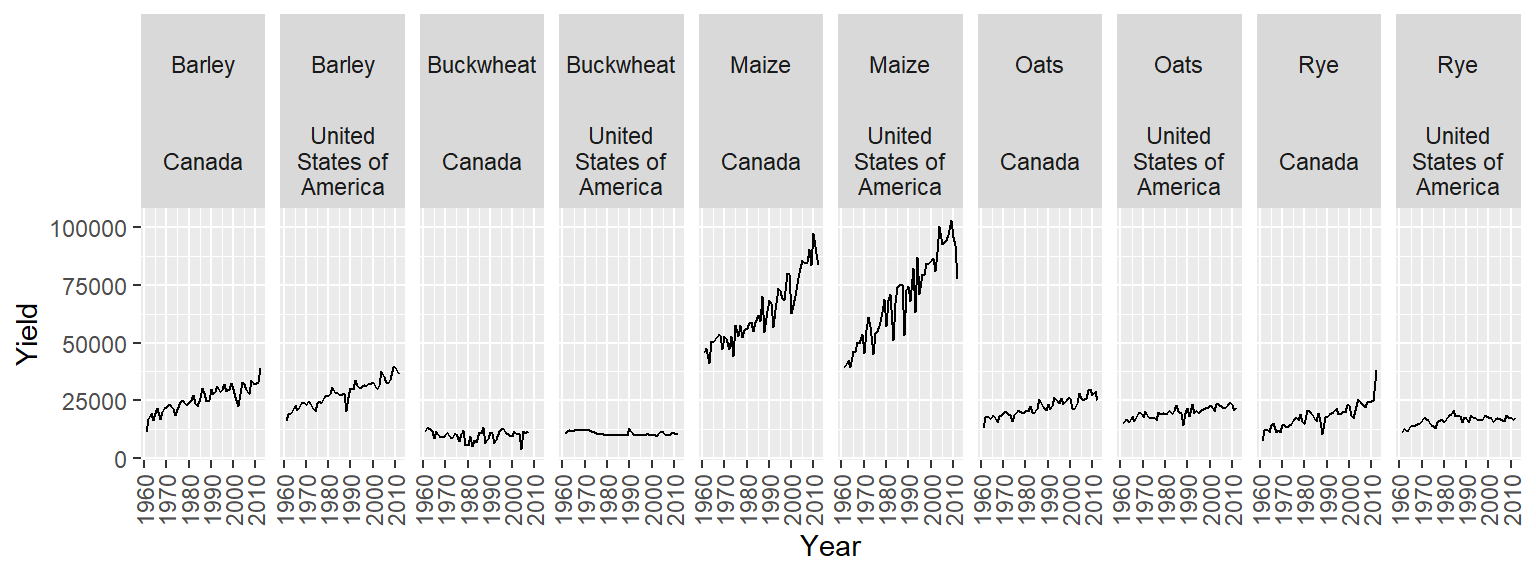
Note that scale_..._gradient() can only be used with continuous variables.
15.5.1.2 Divergent color scheme
One of the scale_..._gradient2() functions can be used to define the middle and end colors. For example, to create a divergent color scheme that converges to a middle income value of $35,000, type:
ggplot(dat2c.med, aes(x = Region, y = Level, fill = Income)) + geom_tile() +
scale_fill_gradient2(low = "darkred", mid = "white", high = "darkgreen",
midpoint = 35000)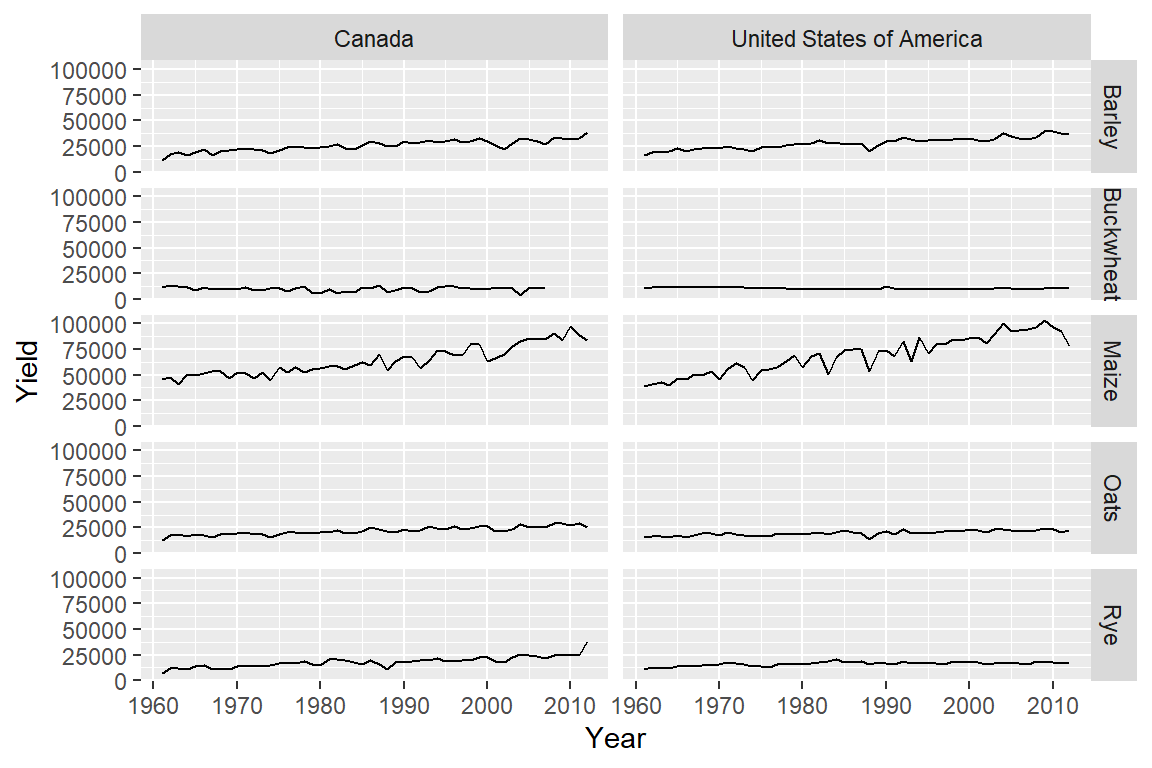
In the last two code chunks, we filled the bars with colors (note the use of functions with the string _fill_). When assigning color to point or line symbols, use the function with the _color_ string. For example:
15.5.2 Categorical color schemes
You can apply one of the following RcolorBrewer categorical palettes in ggplot using one of the scale_..._brewer() functions where, here again, ... is a placeholder for fill or color.
RColorBrewer::display.brewer.all(type = "qual")
For example, to apply the Dark2 palette to the different crop types, type:
ggplot(dat1l, aes(Year, Yield, col = Crop)) +
geom_line() +
guides(color = guide_legend(title = "Crops", reverse = TRUE)) +
scale_color_brewer(palette = "Dark2") 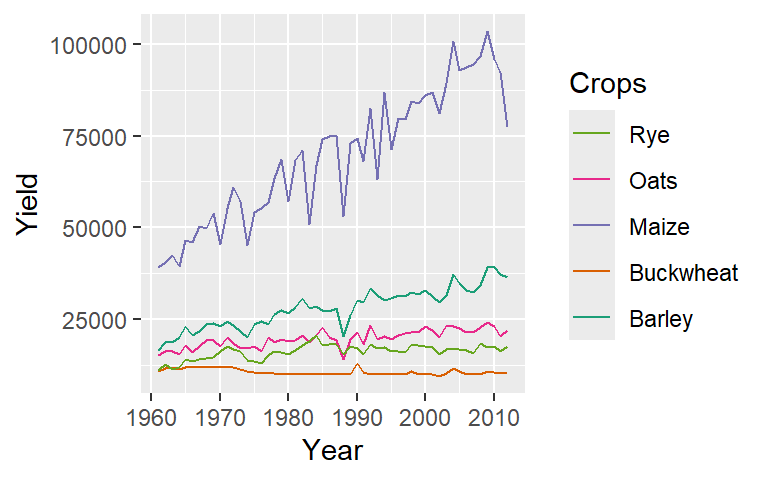
The colors swatches are assigned to the categories in the order they are presented in variable via its levels (if a factor) or alphabetically.
You can also manually choose your colors via the scale_..._manual() functions. For example:
ggplot(dat1l, aes(Year, Yield, col = Crop)) +
geom_line() +
scale_color_manual(values = c("red", "orange", "green", "blue", "yellow"))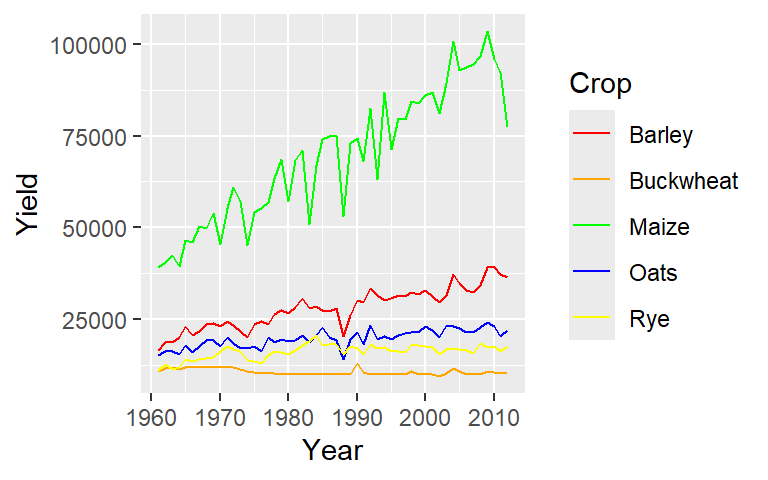
15.5.3 Customizing color breaks
If you want to bin the color swatches using user defined breaks, swap the scale_fill_gradient function with the scale_fill_binned function. In the examples that follow, we use the dat2c.med table that was used to generate a tiled plot earlier in this chapter.
In this example, unequal bin widths are defined for the color map.
ggplot(dat2c.med, aes(x = Region, y = Level, fill = Income)) + geom_tile() +
scale_fill_binned(low = "yellow", high = "red",
breaks = c(21000, 28000, 32000, 42000, 53000))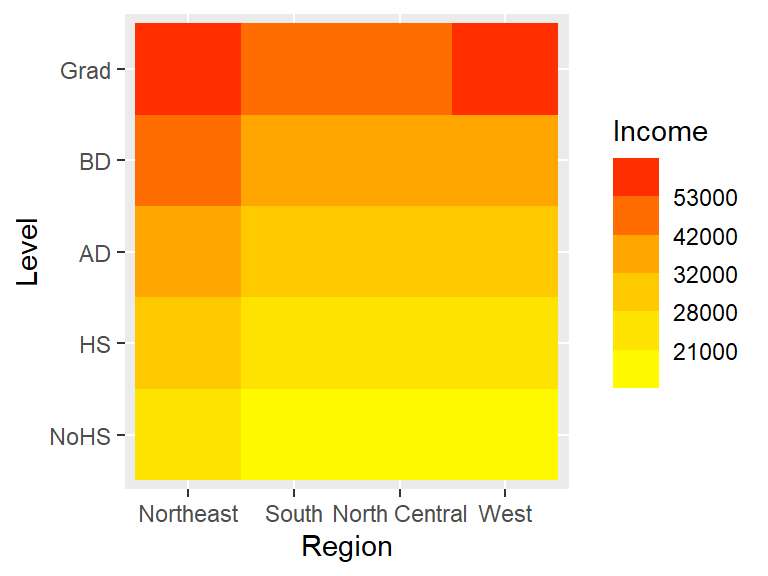
Note how the colorbar does not reflect the unequal bin widths.
As of ggplot2 version 3.3, you can use the guide_colorsteps function to control the colorbar’s look. In the last figure, the breaks are not even, yet the colorbar splits the color swatches into equal length units. Setting the even.steps argument to FALSE scales the color swatches to match the true interval lengths.
ggplot(dat2c.med, aes(x = Region, y = Level, fill = Income)) + geom_tile() +
scale_fill_binned(low = "yellow", high = "red",
breaks = c(21000, 28000, 32000, 42000, 53000),
guide = guide_colorsteps(even.steps = FALSE))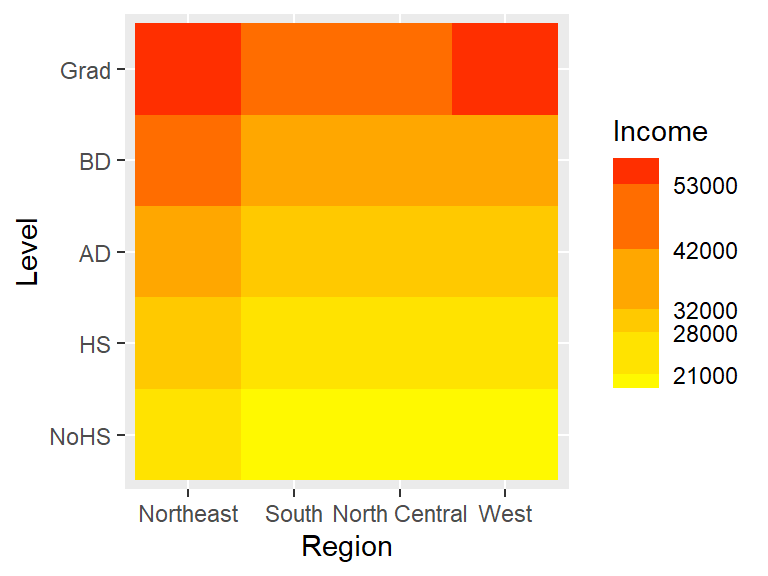
The scale_fill_binned function offers additional control over the legend such as its height (barheight), width (barwidth) and the display of the minimum and maximum values (show.limits).
ggplot(dat2c.med, aes(x = Region, y = Level, fill = Income)) + geom_tile() +
scale_fill_binned(low = "yellow", high = "red",
breaks = c(21000, 28000, 32000, 42000, 53000),
guide = guide_colorsteps(even.steps = FALSE,
barheight = unit(2.3, "in"),
barwidth = unit(0.1, "in"),
show.limits = TRUE))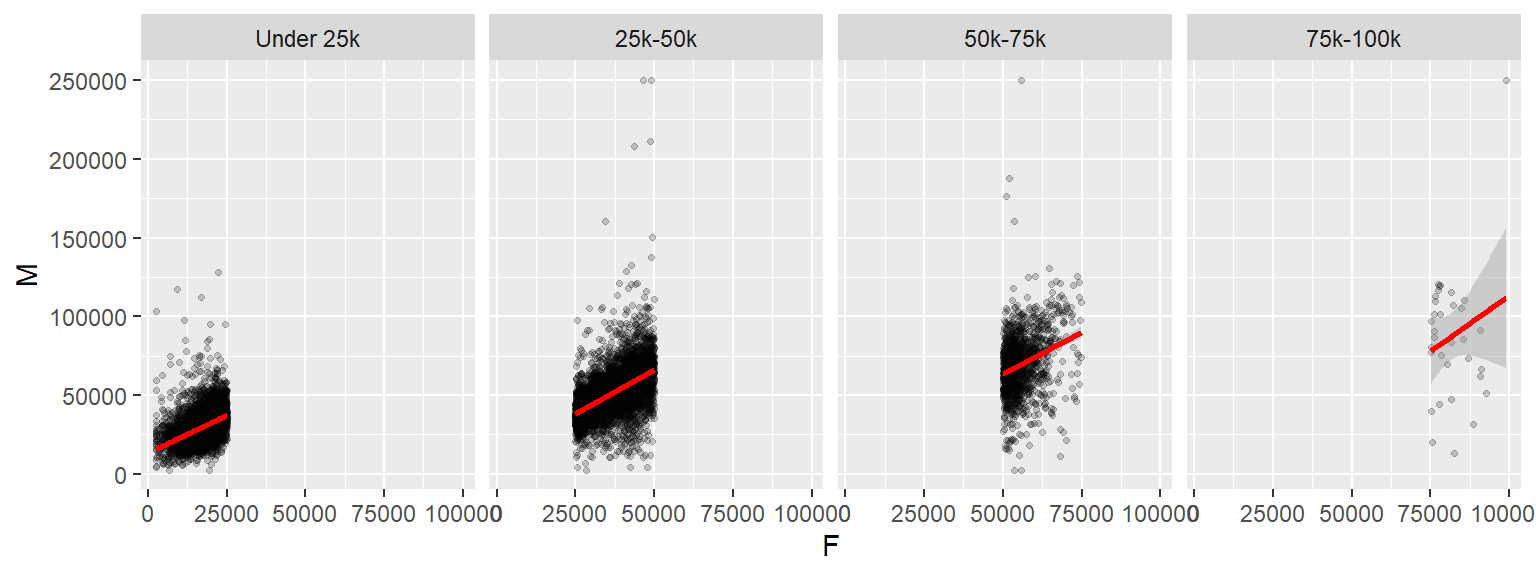
15.5.4 Defining individual colors
You can manually define colors in ggplot2 just as you would in base R. This includes using built-in R color names (retrievable via the colors() function), specifying RGB values with the rgb() function, or using hexadecimal color codes (e.g., "#FF0000" for red and "#FF5933" for a shade of orange)
15.6 Faceting
15.6.1 Faceting by categorical variable
15.6.2 facet_wrap
Faceting (or conditioning on a variable) can be implemented in ggplot2 using the facet_wrap() function.
ggplot(dat1l2, aes(x = Year, y = Yield, color = Crop)) + geom_line() +
facet_wrap( ~ Country, nrow = 1)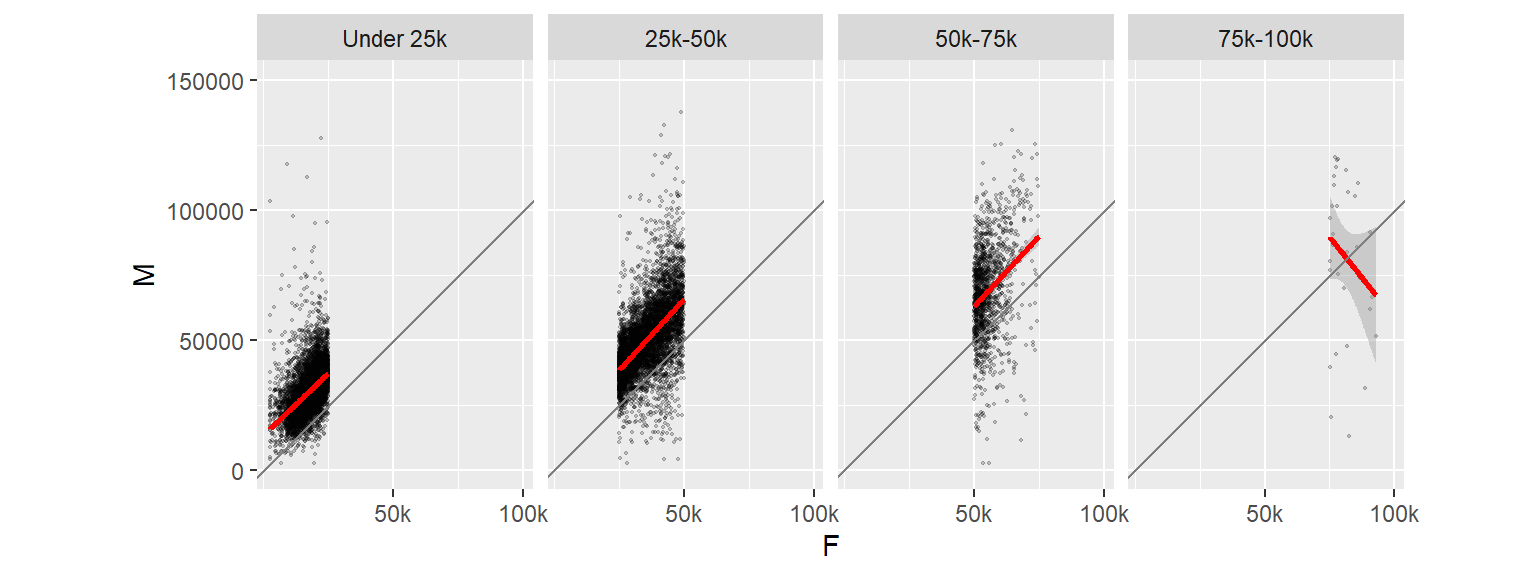
The parameter ~ Country tells ggplot to condition the plots on country. If we wanted the plots to be stacked, we would set nrow to 2.
We can also condition the plots on two variables such as crop and Country. (Note that we will also rotate the x-axis labels to prevent overlaps).
ggplot(dat1l2, aes(x = Year, y=Yield)) + geom_line() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
facet_wrap(Crop ~ Country, nrow = 1)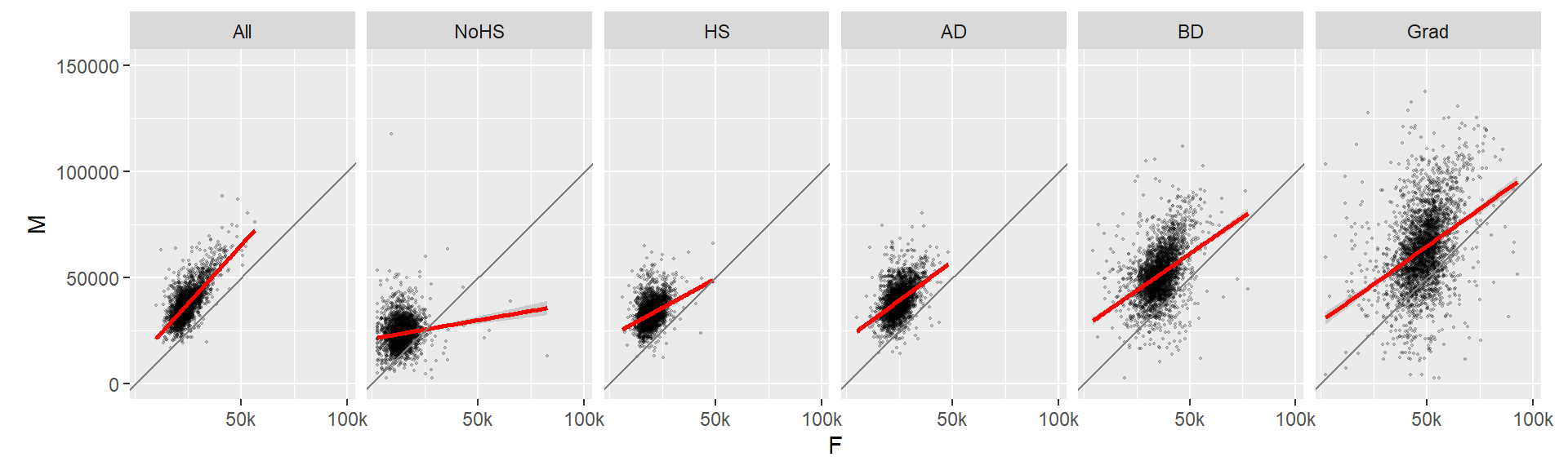
15.6.2.1 Wrapping facet headers
If the header names get truncated in the plot header, you can opt to wrap the facet headers using the label_wrap_gen() function as an argument value to labeler. For example, to wrap the United States of America value, we’ll specify the maximum number of characters per line using the width argument:
ggplot(dat1l2, aes(x = Year, y=Yield)) + geom_line() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
facet_wrap(Crop ~ Country, nrow = 1, labeller = label_wrap_gen(width = 12))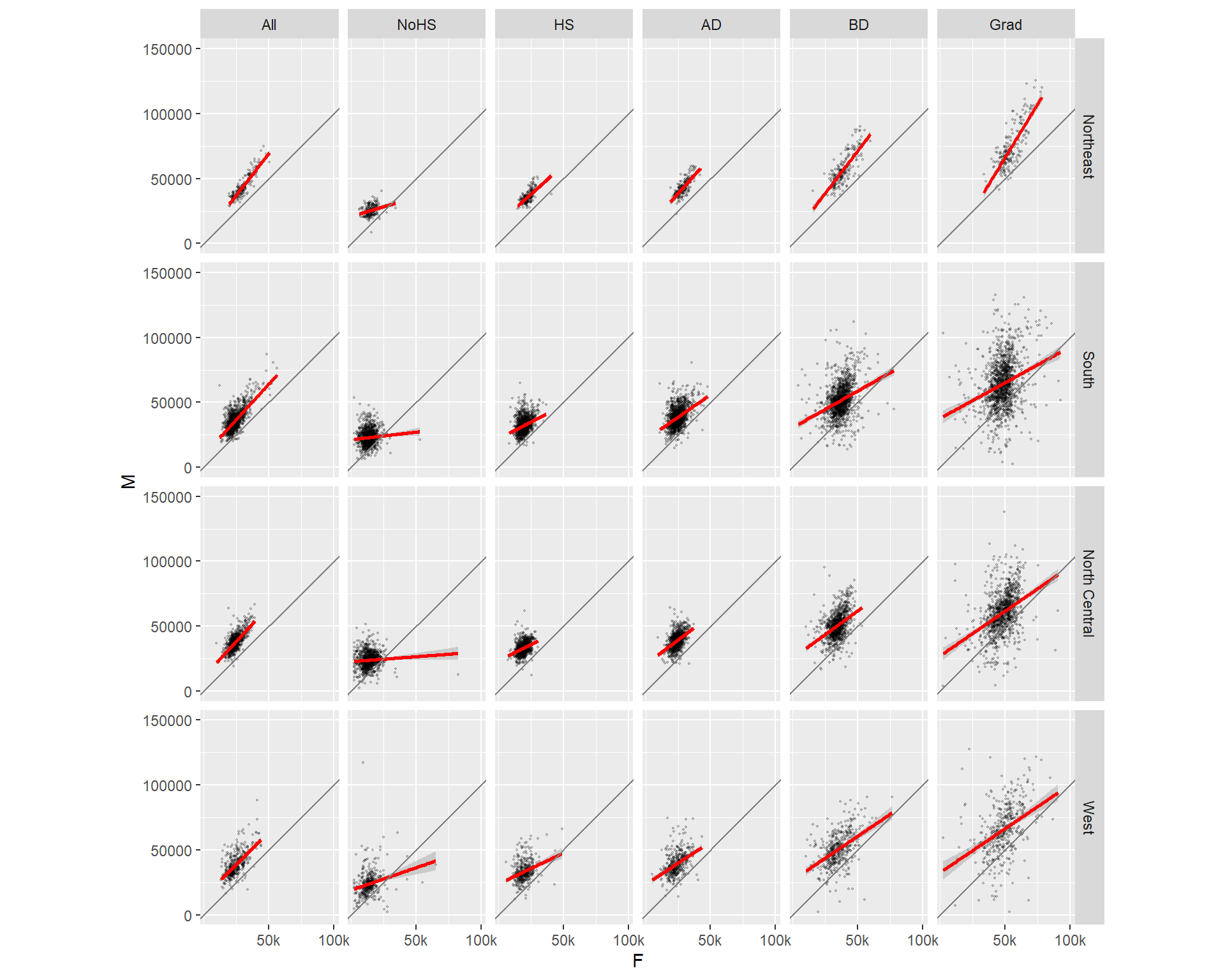
15.6.2.2 facet_grid
The above facet_wrap example generated unique combinations of the variables Crop and Country. But such plots are usually best represented in a grid structure where one variable is spread along one axis and the other variable is spread along another axis of the plot layout. This can be easily accomplished using the facet_grid function:
ggplot(dat1l2, aes(x = Year, y = Yield)) + geom_line() +
facet_grid( Crop ~ Country)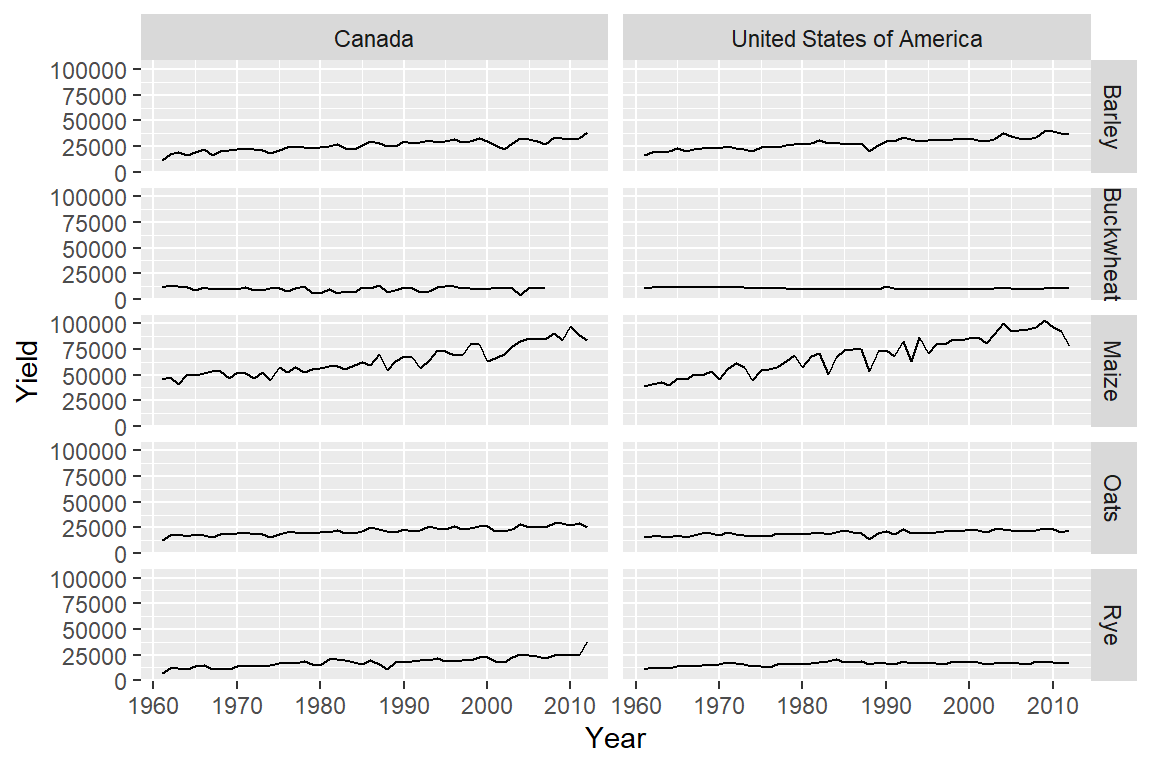
15.6.3 Faceting by continuous variable
In the above examples, we are faceting the plots based on a categorical variable: Country and/or crop. But what if we want to facet the plots based on a continuous variable? For example, we might be interested in comparing male and female incomes across different female income ranges. This requires that a new categorical field (a factor) be created assigning to each case (row) an income group. We can use the cut() function to accomplish this task (we’ll also omit all values greater than 100,000):
dat2c$incrng <- cut(dat2c$F , breaks = c(0, 25000, 50000, 75000, 100000) )
head(dat2c) State County Level Region All F M incrng
1 ak Aleutians East Borough All West 21953 20164 22940 (0,2.5e+04]
2 ak Aleutians East Borough NoHS West 21953 19250 22885 (0,2.5e+04]
3 ak Aleutians East Borough HS West 20770 19671 21192 (0,2.5e+04]
4 ak Aleutians East Borough AD West 26383 26750 26352 (2.5e+04,5e+04]
5 ak Aleutians East Borough BD West 22431 19592 27875 (0,2.5e+04]
6 ak Aleutians East Borough Grad West 74000 74000 71250 (5e+04,7.5e+04]In the above code chunk, we create a new variable, incrng, which is assigned an income category group depending on which range dat2c$F (female income) falls into. The income interval breaks are defined in breaks=. In the output, you will note that the factor incrng defines a range of incomes (e.g. (0 , 2.5e+04]) where the parenthesis ( indicates that the left-most value is exclusive and the bracket ] indicates that the right-most value is inclusive.
However, because we did not create categories that covered all income values in dat2c$F we ended up with a few NA’s in the incrng column:
summary(dat2c$incrng) (0,2.5e+04] (2.5e+04,5e+04] (5e+04,7.5e+04] (7.5e+04,1e+05] NA's
9419 7520 1425 33 5 We will remove all rows associated with missing incrng values:
dat2c <- na.omit(dat2c)
summary(dat2c$incrng) (0,2.5e+04] (2.5e+04,5e+04] (5e+04,7.5e+04] (7.5e+04,1e+05]
9419 7520 1425 33 We can list all unique levels in our newly created factor using the levels() function.
levels(dat2c$incrng) [1] "(0,2.5e+04]" "(2.5e+04,5e+04]" "(5e+04,7.5e+04]" "(7.5e+04,1e+05]"The intervals are not meaningful displayed as is (particularly when scientific notation is adopted). So, we will assign more meaningful names to the factor levels as follows:
levels(dat2c$incrng) <- c("Under 25k", "25k-50k", "50k-75k", "75k-100k")
head(dat2c) State County Level Region All F M incrng
1 ak Aleutians East Borough All West 21953 20164 22940 Under 25k
2 ak Aleutians East Borough NoHS West 21953 19250 22885 Under 25k
3 ak Aleutians East Borough HS West 20770 19671 21192 Under 25k
4 ak Aleutians East Borough AD West 26383 26750 26352 25k-50k
5 ak Aleutians East Borough BD West 22431 19592 27875 Under 25k
6 ak Aleutians East Borough Grad West 74000 74000 71250 50k-75kNote that the order in which the names are passed must match that of the original breaks.
Now we can facet male vs. female scatter plots by income ranges. We will also throw in a best fit line to the plots.
ggplot(dat2c, aes(x = F, y = M)) + geom_point(alpha=0.2, shape=20) +
stat_smooth(method = "lm", col = "red") +
facet_grid( . ~ incrng) 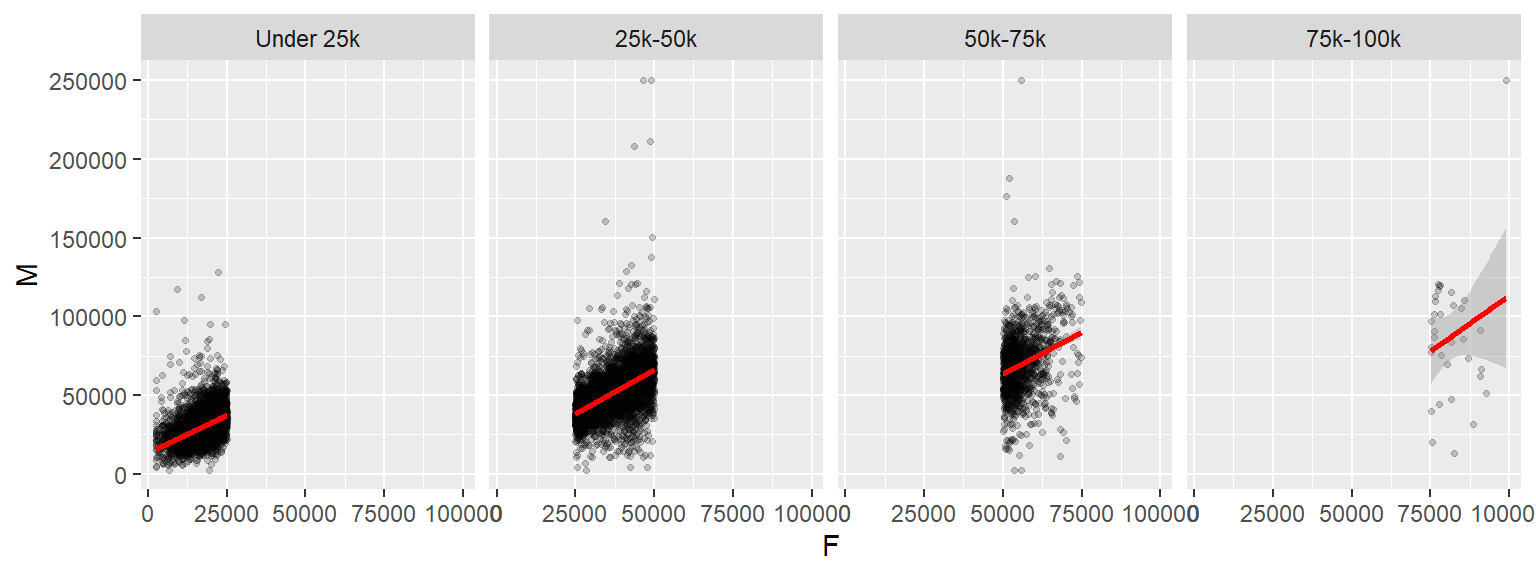
One reason we would want to explore our data across different ranges of value is to assess the consistency in relationship between variables. In our example, this plot helps assess whether the relationship between male and female income is consistent across income groups.
15.7 Adding 45° slope using geom_abline
In this next example, we will add a 45° line using geom_abline where the intercept will be set to 0 and the slope to 1. This will help visualize the discrepancy between the batches of values. So if a point lies above the 45° line, then the male’s income is greater, if the point lies below the line, then the female’s income is greater.
To help highlight differences in income, we will make a few changes to the faceted plots. First, we will reduce the y-axis range to $0-$150k (this will remove a few points from the data); we will force the x-axis and y-axis units to match so that a unit of $50k on the x-axis has the same length as that on the y-axis. We will also reduce the number of x tics and assign shorthand notation to income values (such as “50k” instead of “50000”). All this can be accomplished by adding the scale_x_continuous() function to the stack of ggplot elements.
ggplot(dat2c, aes(x = F, y = M)) + geom_point(alpha = 0.2, shape = 20, size = 0.8) +
ylim(0, 150000) +
stat_smooth(method = "lm", col = "red") +
facet_grid( . ~ incrng) +
coord_equal(ratio = 1) +
geom_abline(intercept = 0, slope = 1, col = "grey50") +
scale_x_continuous(breaks = c(50000, 100000), labels = c("50k", "100k"))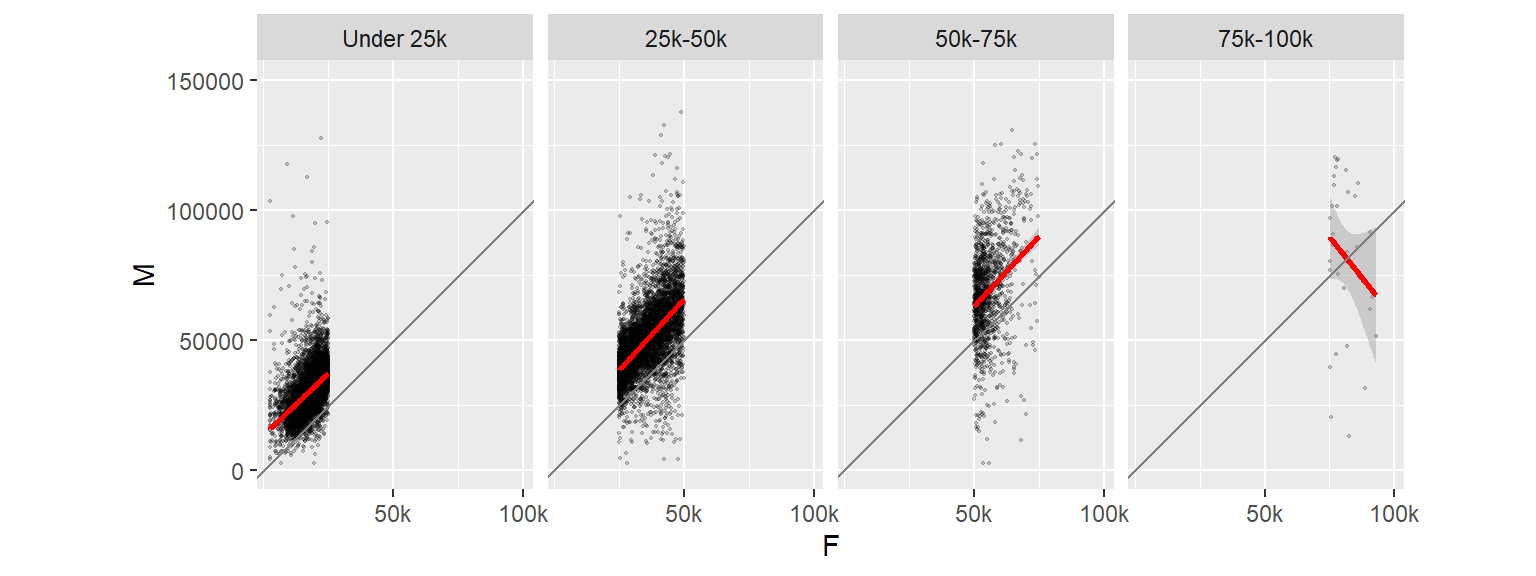
Note the change in regression slope for the last facet. Note that the stat_smooth operation is only applied to the data limited to the axis range defined by ylim.
Now let’s look at the same data but this time conditioned on educational attainment.
# Plot M vs F by educational attainment except for Level == All
ggplot(dat2c, aes(x = F, y = M)) + geom_point(alpha = 0.2, shape = 20, size = 0.8) +
ylim(0, 150000) +
stat_smooth(method = "lm", col = "red") +
facet_grid( . ~ Level) +
coord_equal(ratio = 1) +
geom_abline(intercept = 0, slope = 1, col = "grey50") +
scale_x_continuous(breaks = c(50000, 100000), labels =c("50k", "100k"))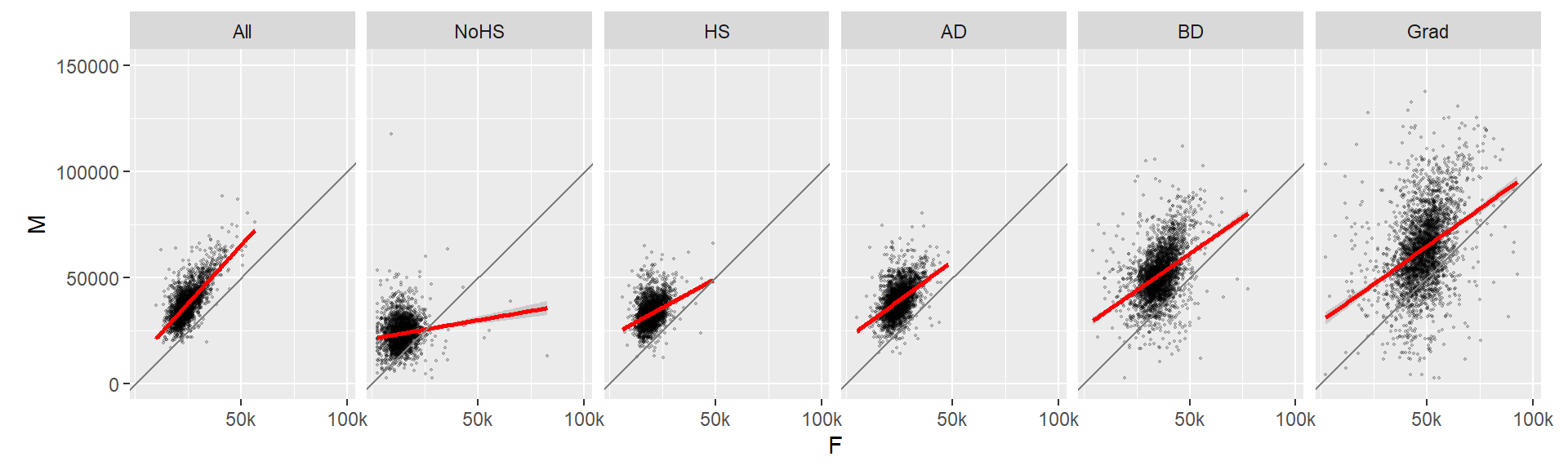
We can also condition the plots on two variables. For example: educational attainment and region.
ggplot(dat2c, aes(x = F, y = M)) + geom_point(alpha = 0.2, shape = 20, size = 0.8) +
ylim(0, 150000) +
stat_smooth(method = "lm", col = "red") +
facet_grid( Region ~ Level) +
coord_equal(ratio = 1) +
geom_abline(intercept = 0, slope = 1, col = "grey50") +
scale_x_continuous(breaks = c(50000, 100000), labels = c("50k", "100k"))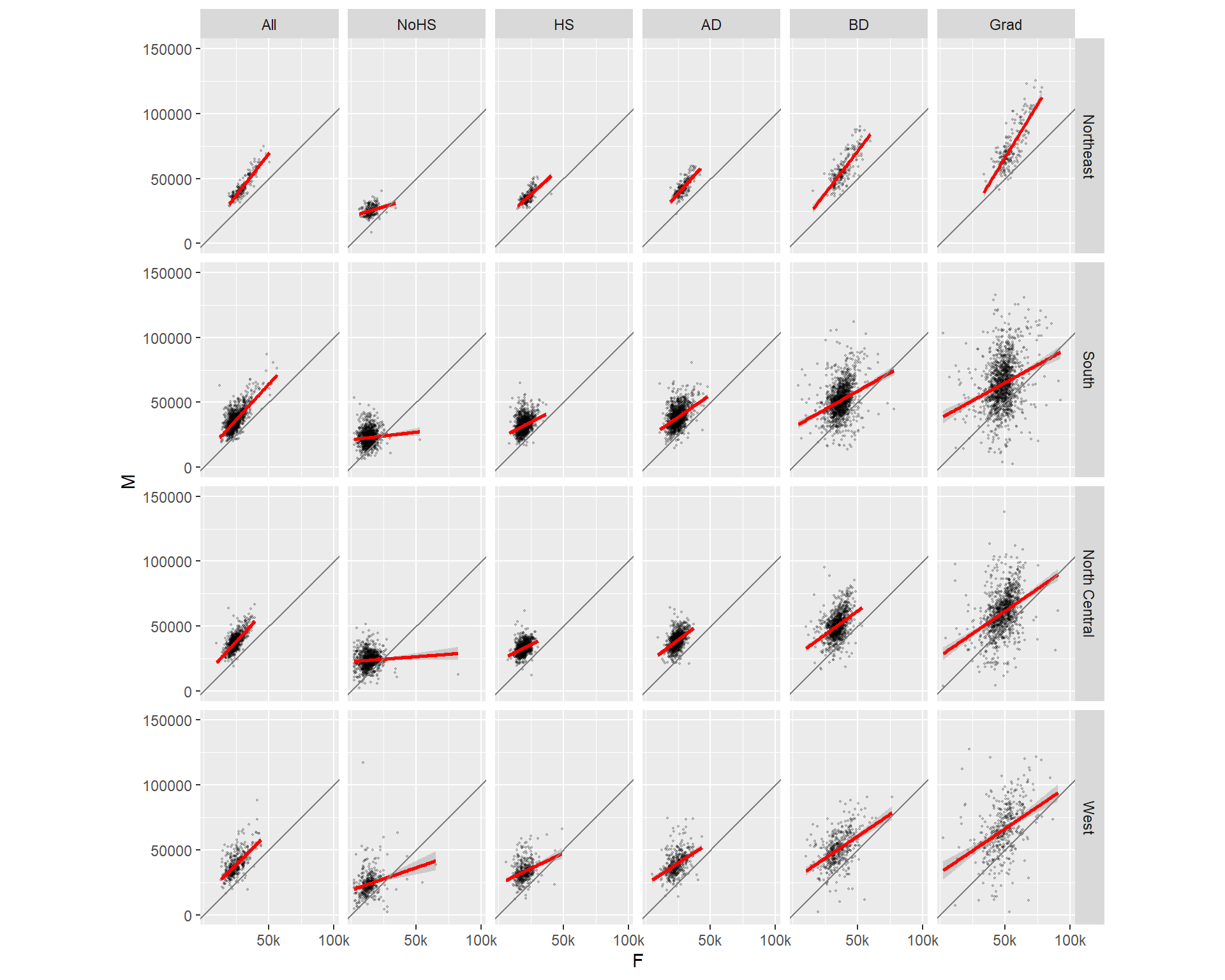
15.8 Exporting to an image
You can export a ggplot figure to an image using the ggsave function. For example,
p1 <- ggplot(dat1l2, aes(x = Year, y = Yield, color = Crop)) + geom_line() +
facet_wrap( ~ Country, nrow = 1) +
scale_y_continuous(labels = scales::label_comma())
ggsave("fig0.png", plot = p1, width = 6, height = 2, units = "in", device = "png")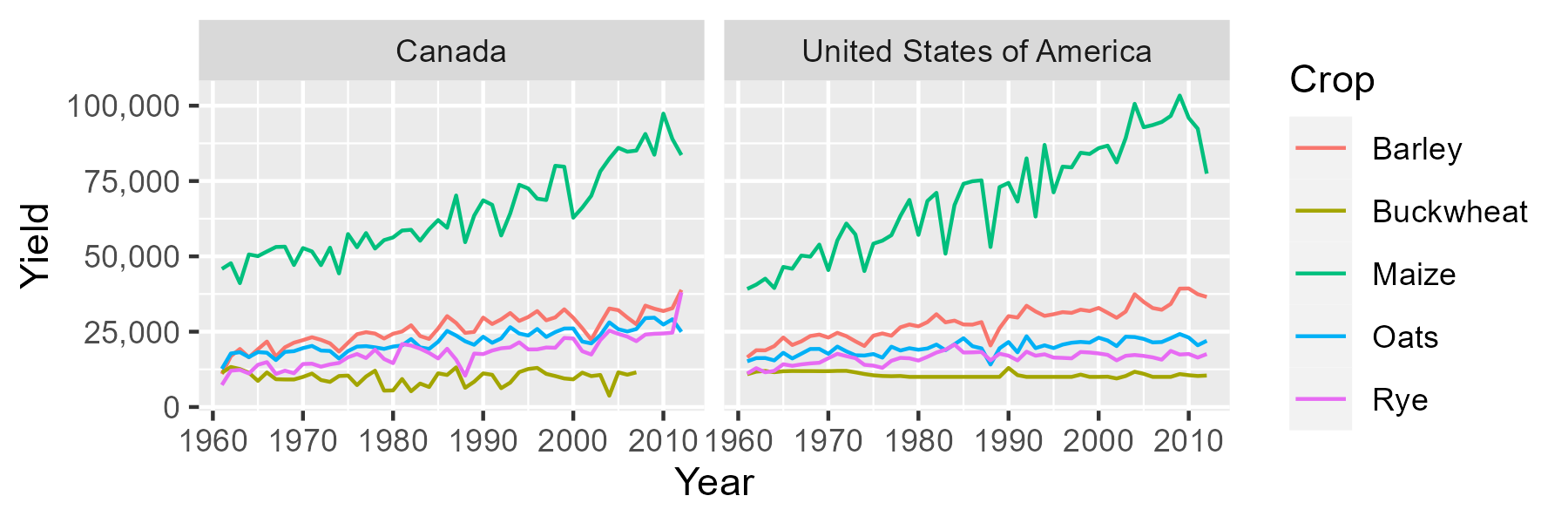
The width and height arguments are defined in units of inches, in. You can also specify these parameters in units of centimeters by setting units = "cm". The device argument controls the image file type. Other file types include "jpeg", "tiff", "bmp" and "svg" just to name a few.
For greater control of the font sizes, you need to make use of the theme function when buiding the plot.
p1 <- ggplot(dat1l2, aes(x = Year, y = Yield, color = Crop)) + geom_line() +
facet_wrap( ~ Country, nrow = 1) +
scale_y_continuous(labels = scales::label_comma()) +
theme(axis.text = element_text(size = 8, family = "mono"),
axis.title = element_text(size = 11, face = "bold"),
strip.text = element_text(size = 11, face="italic", family = "serif"),
legend.title = element_text(size = 10, family = "sans"),
legend.text = element_text(size = 8, color = "grey40"))
ggsave("fig1.png", plot = p1, width = 6, height = 2, units = "in")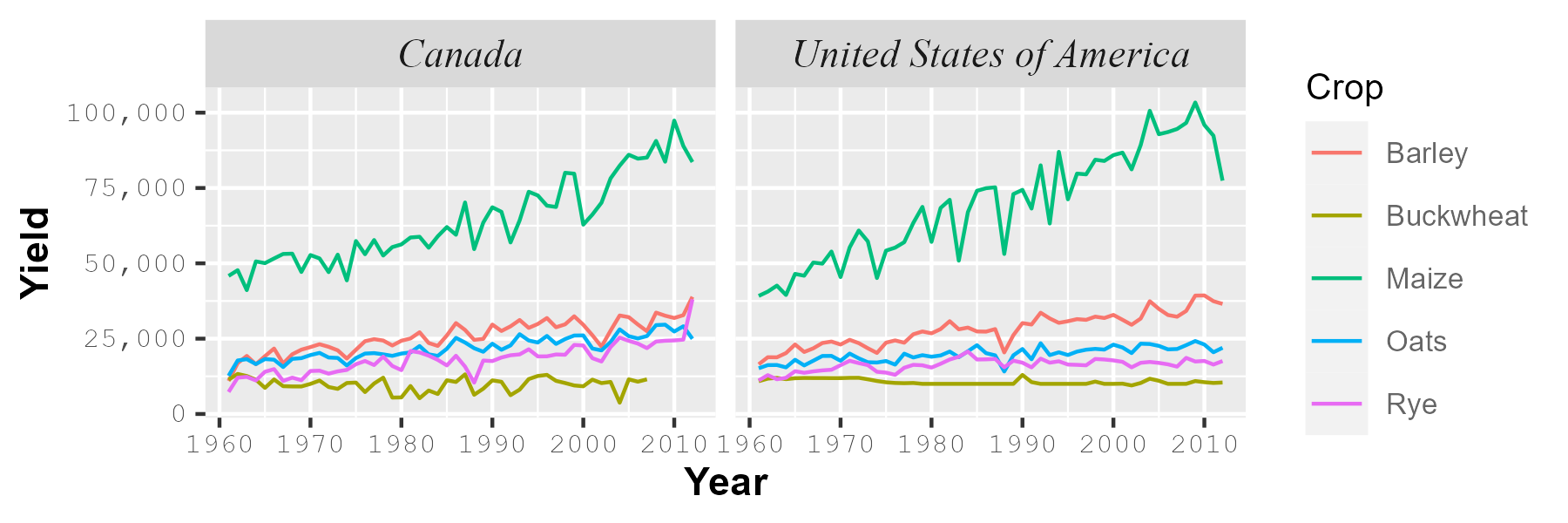
The family argument controls the font type. It does not automatically access all the fonts in your operating system. The three R fonts accessible by default are "serif", "sans" and "mono". These are usually mapped to your system’s fonts.
To access other fonts on your operating system, you will need to make use of the showtext package. The package is not covered in this tutorial, instead, refer to the package’s website for instructions on using the package.