| dplyr |
|---|
| 1.2.0 |
12 Joining Data Tables
dplyr provides functions for joining data from one table to another allowing you to combine information based on shared keys. Four joining functions, each with distinct behavior, are: left_join, right_join, inner_join, and full join.
To demonstrate these functions, we’ll be joining two dataframes: df and dj.
df <- data.frame( x = c(1, 23, 4, 43, 2, 17),
y = c("a", "b", "b", "b", "a", "d"),
stringsAsFactors = FALSE)
df x y
1 1 a
2 23 b
3 4 b
4 43 b
5 2 a
6 17 ddj <- data.frame( z = c("apple", "pear", "orange"),
y = c("a", "b", "c"),
stringsAsFactors = FALSE)
dj z y
1 apple a
2 pear b
3 orange cIn the examples that follow, we will join both tables by the shared key y. A shared key is a column (or set of columns) that appears in both tables and is used to match rows when joining them. It acts like a common identifier that links related data together. Note that the column names do not need to match (see note at the bottom of this page).
12.1 Left join
In this example, if a join element in df does not exist in dj, NA will be assigned to column z. In other words, all elements in df will exist in the output regardless if a matching element is found in dj. Note that the output is sorted in the same order as df (the left table).
library(dplyr)
left_join(df, dj, by="y") x y z
1 1 a apple
2 23 b pear
3 4 b pear
4 43 b pear
5 2 a apple
6 17 d <NA>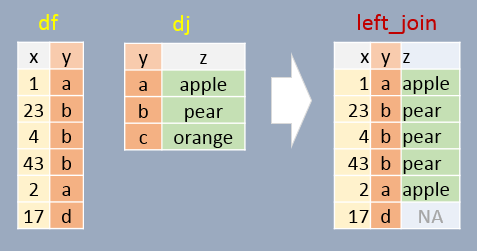
12.2 Right join
If a join element in df does not exist in dj, that element is removed from the output. A few additional important notes follow:
- All elements in
djappear at least once in the output (even if they don’t have a match indfin which case anNAvalue is added); - The output table is sorted in the order in which the
yelements appear indj; - Element
ywill appear as many times as there are matchingy’s indf.
right_join(df, dj, by="y") x y z
1 1 a apple
2 23 b pear
3 4 b pear
4 43 b pear
5 2 a apple
6 NA c orange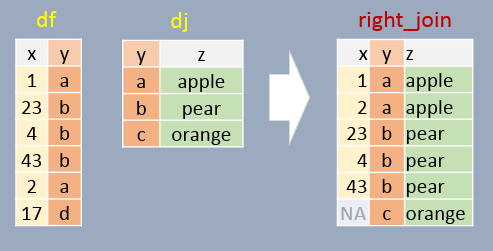
12.3 Inner join
In this example, only matching elements in both df and dj are saved in the output. This is basically an “intersection” of both tables.
inner_join(df, dj, by="y") x y z
1 1 a apple
2 23 b pear
3 4 b pear
4 43 b pear
5 2 a apple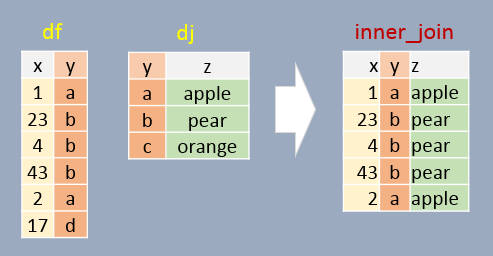
12.4 Full join
In this example, all elements in both df and dj are present in the output. For non-matching pairs, NA values are supplied. This is basically a “union” of both tables.
full_join(df, dj, by="y") x y z
1 1 a apple
2 23 b pear
3 4 b pear
4 43 b pear
5 2 a apple
6 17 d <NA>
7 NA c orange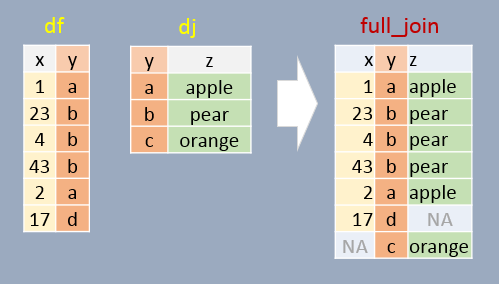
12.5 Joins in a piping operation
The aforementioned joining functions can be used with pipes. For example:
df %>%
left_join(dj, by = "y") x y z
1 1 a apple
2 23 b pear
3 4 b pear
4 43 b pear
5 2 a apple
6 17 d <NA>12.6 A note about shared key names
If the shared keys have different names in each table, you need to specify the by = argument as by = c("left_col" = "right_col"). For example,
library(dplyr)
df <- data.frame( x = c(1, 23, 4, 43, 2, 17),
y1 = c("a", "b", "b", "b", "a", "d"),
stringsAsFactors = FALSE)
dj <- data.frame( z = c("apple", "pear", "orange"),
y2 = c("a", "b", "c"),
stringsAsFactors = FALSE)
left_join(df, dj, by = c("y1" = "y2")) x y1 z
1 1 a apple
2 23 b pear
3 4 b pear
4 43 b pear
5 2 a apple
6 17 d <NA>